
你好,我是看山。
前面写过一篇文章 《如果非要在多线程中使用 ArrayList 会发生什么?》,有读者反馈,Java 11 代码已经修复,还会出现 null 元素。
为了便于理解,当时只是通过代码执行顺序说明了异常原因。其实多线程中还会涉及 Java 内存模型,本文就从这方面说明一下。
对比源码
我们先来看看 Java 11 中,add方法做了什么调整。
Java 8 中add方法的实现:
public boolean add(E e) {
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
}Java 11 中add方法的实现:
public boolean add(E e) {
modCount++;
add(e, elementData, size);
return true;
}
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
size = s + 1;
}两段逻辑的差异在于数组下标是否确定:
elementData[size++] = e;,Java 8 中直接使用size定位并赋值,然后通过size++自增elementData[s] = e; size = s + 1;,Java 11 借助临时变量s定位并赋值,然后通过size = s + 1给size赋新值
Java 11 的优点在于,为数组指定元素赋值的时候,下标值是确定的。也就是说,只要进入add(E e, Object[] elementData, int s)方法中,就只会处理指定位置的数组元素。并且,size的值也是根据s增加。按照执行顺序推断,最终的结果可能会丢数,但是不会出现 null。(多个线程向同一个下标赋值,即s相等,那最终size也相等。)
验证一下
让我们来验证下。
package com.kuaishou.is.datamart;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.CountDownLatch;
public class Main {
public static void main(String[] args) throws InterruptedException {
List<String> list = new ArrayList<>();
CountDownLatch latch = new CountDownLatch(1);
CountDownLatch waiting = new CountDownLatch(3);
Thread t1 = new Thread(() -> {
try {
latch.await();
for (int i = 0; i < 1000; i++) {
list.add("1");
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
waiting.countDown();
}
});
Thread t2 = new Thread(() -> {
try {
latch.await();
for (int i = 0; i < 1000; i++) {
list.add("2");
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
waiting.countDown();
}
});
Thread t2 = new Thread(() -> {
try {
latch.await();
for (int i = 0; i < 1000; i++) {
list.add("2");
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
waiting.countDown();
}
});
t1.start();
t2.start();
latch.countDown();
waiting.await();
System.out.println(list);
}
}在 Java 8 和 Java 11 中分别执行,果然,出现了ArrayIndexOutOfBoundsException和null的情况。如果没有出现,那就是姿势不对,需要多试几次或者多几个线程。
换个角度想问题
上一篇通过代码执行顺序解释了出现问题的原因,这次再看看 JMM 的原因。
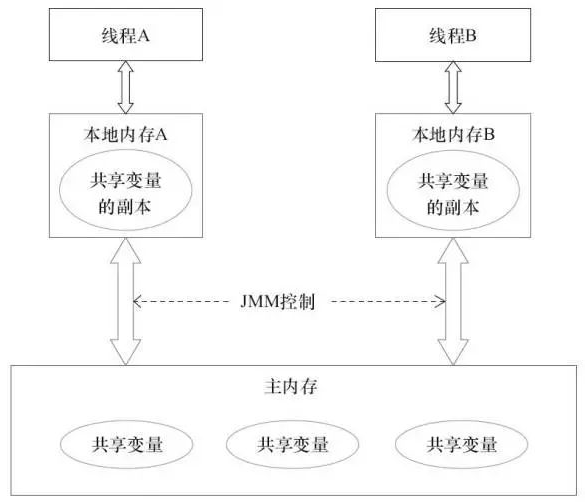
从上图我们可以看到,Java 为每个线程创建了一个本地内存区域,也就是说,代码运行过程中使用的数据,是线程本地缓存的数据。这份缓存的数据,会与主内存的数据做交换(更新主内存数据或更新本次缓存中的数据)。
我们通过一个时序图看下为什么会出现 null(数组越界异常同理):

从时序图我们可以看出现,在执行过程中,两个线程取的size值和elementData数组地址,大部分是操作自己本地缓存中的,执行一段时间后,会将本地缓存中的数据写回主内存数据,然后还会从主内存中读取最新数据更新本地缓存数据。异常就在这个交换过程中发生了。
这个时候,可能有读者会想,是不是把size和elementData两个变量加上volatile就可以解决了。如果这样想,那你就想简单。线程安全是整个类设计实现时已经确定了,除了属性需要考虑多线程的影响,方法(主要是会修改属性元素的方法)也需要考虑。
ArrayList的定位是非线程安全的,其中的所有方法都没有考虑多线程下为共享资源加锁。即使size和elementData两个变量都是实时读写主内存,但是add和grow方法还是可能会覆盖另一个线程的数据。
我们从ArrayList的add方法注释可以得知,方法拆分不是为了实现线程安全,而是为了执行效率和内存占用:
This helper method split out from add(E) to keep method bytecode size under 35 (the -XX:MaxInlineSize default value), which helps when add(E) is called in a C1-compiled loop.
所以说,在多线程场景下使用ArrayList,该出现的异常,一个也不会少。
推荐阅读
你好,我是看山,公众号:看山的小屋,10 年老猿,开源贡献者。游于码界,戏享人生。
个人主页:https://www.howardliu.cn
个人博文:如果非要在多线程中使用 ArrayList 会发生什么?(第二篇)
CSDN 主页:http://kanshan.csdn.net/
CSDN 博文:如果非要在多线程中使用 ArrayList 会发生什么?(第二篇)
