你好,我是看山。

你好,我是看山。
本文收录在 《从小工到专家的 Java 进阶之旅》 系列专栏中。
从 2017 年开始,Java 版本更新策略从原来的每两年一个新版本,改为每六个月一个新版本,以快速验证新特性,推动 Java 的发展。让我们跟随 Java 的脚步,配合示例讲解,看一看每个版本的新特性,本期是 Java21 的新特性。
概述
Java21 在 2023 年 9 月 19 日发布GA版本,Java21是长期支持版(LTS,Long-Term Support),共十五大特性:
- JEP 430: 字符串模板(String Templates,预览)
- JEP 431: 有序集合(Sequenced Collections)
- JEP 439: 分代ZGC(Generational ZGC)
- JEP 440: Record模式(Record Patterns)
- JEP 441: switch模式匹配(Pattern Matching for switch)
- JEP 442: 外部函数和内存API(Foreign Function & Memory API,FFM API,第三次预览)
- JEP 443: 未命名模式和变量(Unnamed Patterns and Variables,预览)
- JEP 444: 虚拟线程(Virtual Threads)
- JEP 445: 未命名类和示例main方法(Unnamed Classes and Instance Main Methods,预览)
- JEP 446: 作用域值(Scoped Values,预览)
- JEP 448: 向量API(Vector API,第六次孵化)
- JEP 449: 启用Windows32位 x86支持(Deprecate the Windows 32-bit x86 Port for Removal)
- JEP 451: 准备禁止动态加载代理(Prepare to Disallow the Dynamic Loading of Agents)
- JEP 452: 密钥封装机制 API(Key Encapsulation Mechanism API)
- JEP 453: 结构化并发API(Structured Concurrency,预览)
接下来我们一起看看这些特性。
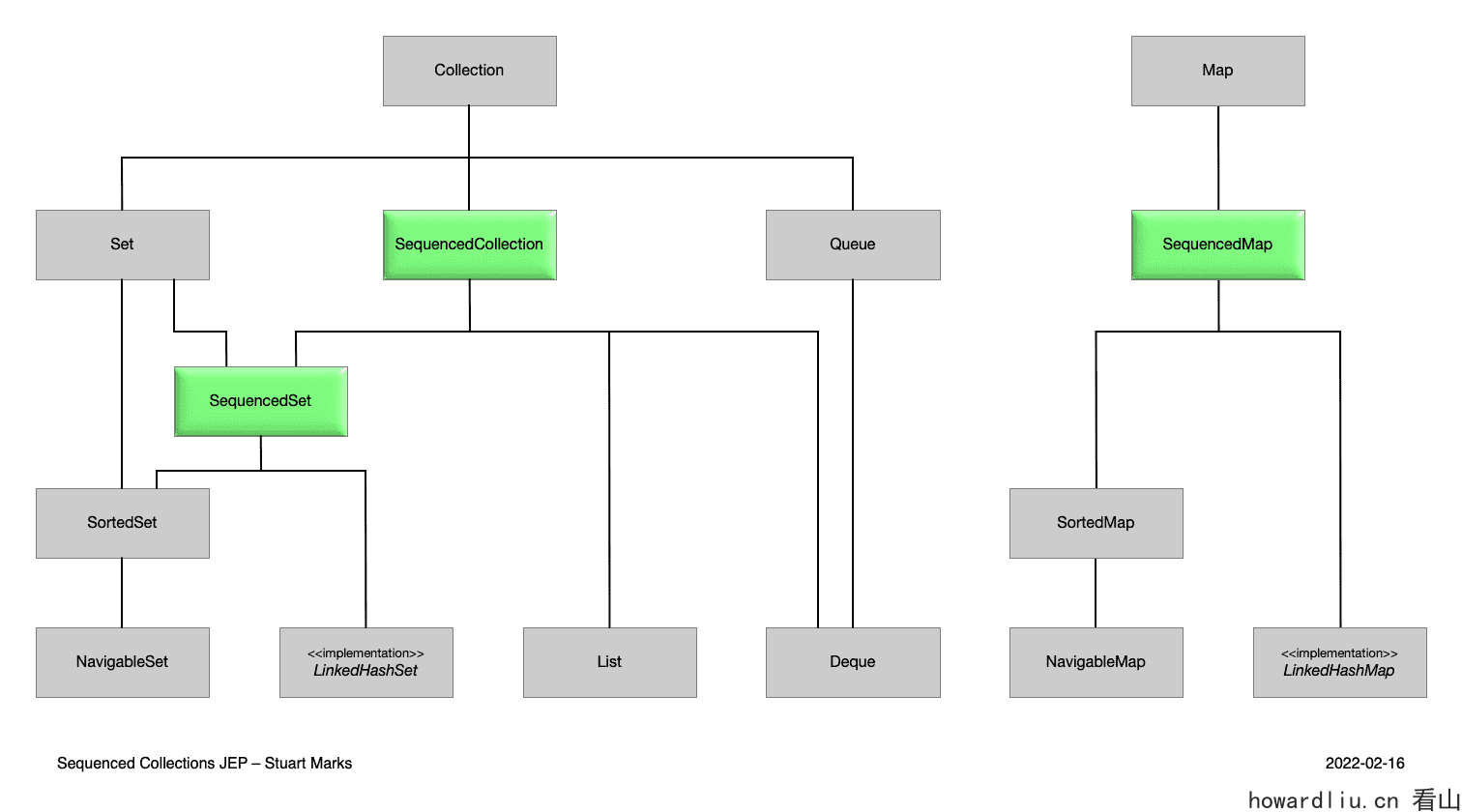
JEP 431: 有序集合(Sequenced Collections)
JEP 431:有序集合是Java21版本中引入的一个新特性,旨在为Java集合框架添加对有序集合的支持。
有序集合是一种具有定义好的元素访问顺序的集合类型,它允许以一致的方式访问和处理集合中的元素,无论是从第一个元素到最后一个元素,还是从最后一个元素到第一个元素。
在 Java 中,集合类库非常重要且使用频率非常高,但是缺乏一种能够表示具有定义好的元素访问顺序的集合类型。
例如,List和Deque都定义了元素的访问顺序,但它们的共同父接口Collection却没有。同样,Set不定义元素的访问顺序,其子类型如HashSet也没有定义,但子类型如SortedSet和LinkedHashSet则有定义。因此,支持访问顺序的功能散布在整个类型层次结构中,使得在API中表达某些有用的概念变得困难。Collection太通用,将此类约束留给文档规范,可能导致难以调试的错误。
而且,虽然某些集合有顺序操作方法,但是却不尽相同,比如
| First element | Last element | |
|---|---|---|
| List | list.get(0) | list.get(list.size() - 1) |
| Deque | deque.getFirst() | deque.getLast() |
| SortedSet | sortedSet.first() | sortedSet.last() |
| LinkedHashSet | linkedHashSet.iterator().next() | 缺失 |
于是在Java21提供了有序集合SequencedCollection、SequencedSet、SequencedMap:
interface SequencedCollection<E> extends Collection<E> {
// new method
SequencedCollection<E> reversed();
// methods promoted from Deque
void addFirst(E);
void addLast(E);
E getFirst();
E getLast();
E removeFirst();
E removeLast();
}
interface SequencedSet<E> extends Set<E>, SequencedCollection<E> {
SequencedSet<E> reversed(); // covariant override
}
interface SequencedMap<K,V> extends Map<K,V> {
// new methods
SequencedMap<K,V> reversed();
SequencedSet<K> sequencedKeySet();
SequencedCollection<V> sequencedValues();
SequencedSet<Entry<K,V>> sequencedEntrySet();
V putFirst(K, V);
V putLast(K, V);
// methods promoted from NavigableMap
Entry<K, V> firstEntry();
Entry<K, V> lastEntry();
Entry<K, V> pollFirstEntry();
Entry<K, V> pollLastEntry();
}SequencedCollection的reversed()方法提供了一个原始集合的反向视图。任何对原始集合的修改都会在视图中可见。如果允许,视图中的修改会写回到原始集合。
我们看一个例子,假设我们有一个LinkedHashSet,现在我们想要获取它的反向视图并以反向顺序遍历它:
LinkedHashSet<Integer> linkedHashSet = new LinkedHashSet<>(Arrays.asList(3, 2, 1));
// 获取反向视图
SequencedCollection<Integer> reversed = linkedHashSet.reversed();
// 反向遍历
System.out.println("原始数据:" + linkedHashSet);
System.out.println("反转数据:" + reversed);
// 运行结果:
// 原始数据:[3, 2, 1]
// 反转数据:[1, 2, 3]这些方法都是便捷方法,内部数据结构没有变化,其实本质也是原来的用法。比如ArrayList中的getFirst和getLast方法:
/**
* {@inheritDoc}
*
* @throws NoSuchElementException {@inheritDoc}
* @since 21
*/
public E getFirst() {
if (size == 0) {
throw new NoSuchElementException();
} else {
return elementData(0);
}
}
/**
* {@inheritDoc}
*
* @throws NoSuchElementException {@inheritDoc}
* @since 21
*/
public E getLast() {
int last = size - 1;
if (last < 0) {
throw new NoSuchElementException();
} else {
return elementData(last);
}
}JEP 439: 分代ZGC(Generational ZGC)
ZGC从Java11开始预览,Java15提供生产支持,Java16增加并发线程堆栈处理,发展到Java21提供了分代ZGC,具体发展历程可以查看https://wiki.openjdk.org/display/zgc/Main。
江湖传说,ZGC(Z Garbage Collector)的Z表示最后一个GC,可见其雄心勃勃。而分代ZGC的出现,就是革自己的命。
与非分代ZGC相比,在不影响吞吐量的的情况下,带来更多的好处:
- 更低的分配停顿风险;
- 更低的堆内存开销;
- 更低的CPU开销。
分代ZGC的目标是:
- 暂停时间不超过1ms(ZGC的目标是10ms)
- 支持从几M字节到几T字节的堆大小;
- 尽量少的配置。
在Java21中,分代ZGC的实现细节主要包括以下几个方面:
- 分代设计:基于「大部分对象朝生夕死」的分代假说,分代ZGC将内存划分为年轻代和老年代,并为这两种代分别维护不同的垃圾收集策略。这种设计可以更有效地处理不同生命周期的对象,从而提高整体性能。
- 彩色指针结构:分代ZGC使用彩色指针结构来优化内存访问。元数据被放在指针的低阶位,而对象地址被放在高阶位。这种结构可以减少加载屏障中的机器指令数量,从而提高性能。
- 写屏障技术:分代ZGC引入了写屏障技术,以确保在对象年龄更新时能够正确地通知垃圾收集器。这有助于减少垃圾收集过程中对应用程序的影响。
- 内存管理优化:通过分代收集,分代ZGC可以更频繁地对新生代进行垃圾收集,从而减少分配停顿的风险,降低内存开销,并减少垃圾收集的CPU开销。
我们可以通过命令-XX:+UseZGC -XX:+ZGenerational使用分代ZGC。
为了平稳的过渡,在Java21中必须增加-XX:+ZGenerational参数,显性的指明使用分代ZGC,在未来,非分代ZGC将被移除,ZGenerational参数也就作废了。
我们看下Hazelcast Jet on Generational ZGC中给出的测评效果:
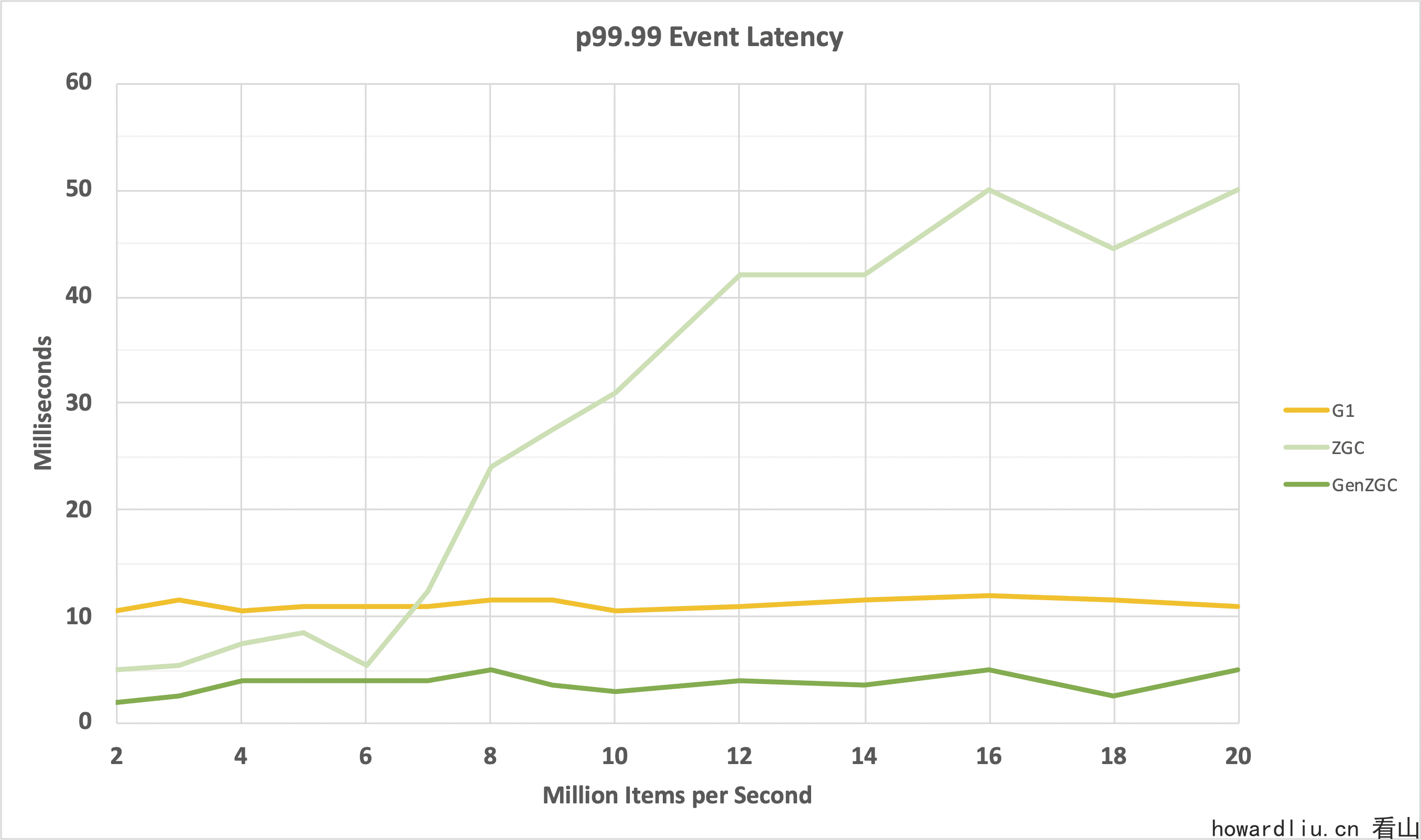
从上图可以看到,非分代 ZGC 在低负载下表现非常好,但随着分配压力的增加,延迟也会增加。使用分代 ZGC 后,即使在高负载下,延迟也非常低,而且延迟效果优于G1。
JEP 440: Record模式(Record Patterns)
Record类型提供不可变对象的简单实现(其实就是Java Bean,但是省略一堆的getter、setter、hashcode、equals、toString等方法),Java16开始一直在演化增强(参见从小工到专家的 Java 进阶之旅)。
Record模式归属于Amber项目的一部分,Amber项目旨在通过小而美的方式,增强Java语言特性。本次的Record模式,主要是使Record类型可以直接在instanceof和switch模式匹配中使用。
Record模式最初作为预览功能在JEP 405中提出,并在Java19中交付。JEP 432提出了第二次预览,基于持续的经验和反馈进行了进一步的完善。终于在JEP 440正式转正。
我们一起看个示例,比如有下面几个基础元素:
// 颜色
enum Color { RED, GREEN, BLUE}
// 点
record Point(int x, int y) {}
// 带颜色的点
record ColoredPoint(Point p, Color color) {}
// 正方形
record Square(ColoredPoint upperLeft, ColoredPoint lowerRight) {}我们分别通过instanceof模式匹配和switch模式匹配判断输入参数的类型,打印不同的格式:
private static void instancePatternsAndPrint(Object o) {
if (o instanceof Square(ColoredPoint upperLeft, ColoredPoint lowerRight)) {
System.out.println("Square类型:" + upperLeft + " " + lowerRight);
} else if (o instanceof ColoredPoint(Point(int x, int y), Color color)) {
System.out.println("ColoredPoint类型:" + x + " " + y + " " + color);
} else if (o instanceof Point p) {
System.out.println("Point类型:" + p);
}
}
private static void switchPatternsAndPrint(Object o) {
switch (o) {
case Square(ColoredPoint upperLeft, ColoredPoint lowerRight) -> {
System.out.println("Square类型:" + upperLeft + " " + lowerRight);
}
case ColoredPoint(Point(int x, int y), Color color) -> {
System.out.println("ColoredPoint类型:" + x + " " + y + " " + color);
}
case Point p -> {
System.out.println("Point类型:" + p);
}
default -> throw new IllegalStateException("Unexpected value: " + o);
}
}我们通过main方法执行下:
public static void main(String[] args) {
var p = new Point(1, 2);
var cp1 = new ColoredPoint(p, Color.RED);
var cp2 = new ColoredPoint(p, Color.GREEN);
var square = new Square(cp1, cp2);
instancePatternsAndPrint(square);
instancePatternsAndPrint(cp1);
instancePatternsAndPrint(p);
switchPatternsAndPrint(square);
switchPatternsAndPrint(cp1);
switchPatternsAndPrint(p);
}
// 结果是:
//
// Square类型:ColoredPoint[p=Point[x=1, y=2], color=RED] ColoredPoint[p=Point[x=1, y=2], color=GREEN]
// ColoredPoint类型:1 2 RED
// Point类型:Point[x=1, y=2]
//
// Square类型:ColoredPoint[p=Point[x=1, y=2], color=RED] ColoredPoint[p=Point[x=1, y=2], color=GREEN]
// ColoredPoint类型:1 2 RED
// Point类型:Point[x=1, y=2]JEP 441: switch模式匹配(Pattern Matching for switch)
switch模式经过四次预览,终于转正。
switch模式匹配是一个非常赞的功能,可以在选择器表达式使用基础判断和任意引用类型,包括instanceof操作符。这意味着可以更灵活地使用对象、数组、列表等复杂数据结构作为switch语句的基础,从而简化代码并提高可读性。
switch模式匹配允许在switch语句中使用模式来测试表达式,每个模式都有特定的动作,从而可以简洁、安全地表达复杂的数据导向查询。
通过代码看下switch模式匹配的魅力;
static String formatValue(Object obj) {
return switch (obj) {
case null -> "null";
case Integer i -> String.format("int %d", i);
case Long l -> String.format("long %d", l);
case Double d -> String.format("double %f", d);
case String s -> String.format("String %s", s);
case Person(String name, String address) -> String.format("Person %s %s", name, address);
default -> obj.toString();
};
}
public record Person(String name, String address) {}
public static void main(String[] args) {
System.out.println(formatValue(10));
System.out.println(formatValue(20L));
System.out.println(formatValue(3.14));
System.out.println(formatValue("Hello"));
System.out.println(formatValue(null));
System.out.println(formatValue(new Person("Howard", "Beijing")));
}
// 运行结果
// int 10
// long 20
// double 3.140000
// String Hello
// null
// Person Howard BeijingJEP 444: 虚拟线程(Virtual Threads)
虚拟线程是一种轻量级的线程实现,旨在显著降低编写、维护和观察高吞吐量并发应用程序的难度。它们占用的资源少,不需要被池化,可以创建大量虚拟线程,特别适用于IO密集型任务,因为它们可以高效地调度大量虚拟线程来处理并发请求,从而显著提高程序的吞吐量和响应速度。
虚拟线程有下面几个特点:
- 轻量级:虚拟线程是JVM内部实现的轻量级线程,不需要操作系统内核参与,创建和上下文切换的成本远低于传统的操作系统线程(即平台线程),且占用的内存资源较少。
- 减少CPU时间消耗:由于虚拟线程不依赖于操作系统平台线程,因此在进行线程切换时耗费的CPU时间会大大减少,从而提高了程序的执行效率。
- 简化多线程编程:虚拟线程通过结构化并发API来简化多线程编程,使得开发者可以更容易地编写、维护和观察高吞吐量并发应用程序。
- 适用于大量任务场景:虚拟线程非常适合需要创建和销毁大量线程的任务、需要执行大量计算的任务(如数据处理、科学计算等)以及需要实现任务并行执行以提高程序性能的场景。
- 提高系统吞吐量:通过对虚拟线程的介绍和与Go协程的对比,可以看出虚拟线程能够大幅提高系统的整体吞吐量。
不考虑虚拟线程实现原理,对开发者而言,使用体验上与传统线程几乎没有区别。我们一起试用下。
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
IntStream.range(0, 10_000).forEach(i -> {
executor.submit(() -> {
Thread.sleep(Duration.ofSeconds(1));
System.out.println(Thread.currentThread().getName() + ": " + i);
return i;
});
});
}
Thread.startVirtualThread(() -> {
System.out.println("Hello from a virtual thread[Thread.startVirtualThread]");
});
final ThreadFactory factory = Thread.ofVirtual().factory();
factory.newThread(() -> {
System.out.println("Hello from a virtual thread[ThreadFactory.newThread]");
})
.start();虚拟线程为了降低使用门槛,直接提供了与原生线程类似的方法:
Executors.newVirtualThreadPerTaskExecutor(),可以像普通线程池一样创建虚拟线程。Thread.startVirtualThread,通过工具方法直接创建并运行虚拟线程。Thread.ofVirtual().factory().newThread(),另一个工具方法可以创建并运行虚拟线程。Thread还有一个ofPlatform()方法,用来构建普通线程。
通过本地简单测试(在「公众号:看山的小屋」回复”java”获取源码),1w个模拟线程运行时,性能方面虚拟线程 > 线程池。
需要注意的是,虚拟线程适用于IO密集场景,而非CPU密集的场景。
JEP 452: 密钥封装机制 API(Key Encapsulation Mechanism API, KEM API)
KEM是一种现代加密技术,它通过使用非对称或公钥密码学来保护对称密钥。与传统的加密方法不同,KEM使用公钥的属性来派生一个相关的对称密钥,这个过程不需要填充,因此可以更容易地证明其安全性。
KEM的工作流程
- 密钥对生成函数:返回包含公钥和私钥的一对密钥。
- 密钥封装函数:由发送方调用,接受接收方的公钥和加密选项;返回一个秘密密钥K和一个密钥封装消息(在ISO 18033-2中称为ciphertext)。发送方将密钥封装消息发送给接收方。
- 密钥解封函数:由接收方调用,接受接收方的私钥和收到的密钥封装消息;返回秘密密钥K。
据说这种算法是可以解决量子计算威胁,若有有安全需求,可以深入研究下。
预览功能
JEP 430: 字符串模板(String Templates,预览)
字符串模板是一个值得期待的功能,Java21中提供了预览版。
字符串模板通过将文本和嵌入式表达式结合在一起,使得Java程序能够以一种更加直观和安全的方式构建字符串。与传统的字符串拼接(使用+操作符)、StringBuilder或String.format 等方法相比,字符串模板提供了一种更加清晰和安全的字符串构建方式。特别是当字符串需要从用户提供的值构建并传递给其他系统时(例如,构建数据库查询),使用字符串模板可以有效地验证和转换模板及其嵌入表达式的值,从而提高Java程序的安全性。
让我们通过代码看一下这个特性的魅力:
public static void main(String[] args) {
// 拼装变量
String name = "看山";
String info = STR. "My name is \{ name }" ;
assert info.equals("My name is 看山");
// 拼装变量
String firstName = "Howard";
String lastName = "Liu";
String fullName = STR. "\{ firstName } \{ lastName }" ;
assert fullName.equals("Howard Liu");
String sortName = STR. "\{ lastName }, \{ firstName }" ;
assert sortName.equals("Liu, Howard");
// 模板中调用方法
String s2 = STR. "You have a \{ getOfferType() } waiting for you!" ;
assert s2.equals("You have a gift waiting for you!");
Request req = new Request("2017-07-19", "09:15", "https://www.howardliu.cn");
// 模板中引用对象属性
String s3 = STR. "Access at \{ req.date } \{ req.time } from \{ req.address }" ;
assert s3.equals("Access at 2017-07-19 09:15 from https://www.howardliu.cn");
LocalTime now = LocalTime.now();
String markTime = DateTimeFormatter
.ofPattern("HH:mm:ss")
.format(now);
// 模板中调用方法
String time = STR. "The time is \{
// The java.time.format package is very useful
DateTimeFormatter
.ofPattern("HH:mm:ss")
.format(now)
} right now" ;
assert time.equals("The time is " + markTime + " right now");
// 模板嵌套模板
String[] fruit = {"apples", "oranges", "peaches"};
String s4 = STR. "\{ fruit[0] }, \{
STR. "\{ fruit[1] }, \{ fruit[2] }"
}" ;
assert s4.equals("apples, oranges, peaches");
// 模板与文本块结合
String title = "My Web Page";
String text = "Hello, world";
String html = STR. """
<html>
<head>
<title>\{ title }</title>
</head>
<body>
<p>\{ text }</p>
</body>
</html>
""" ;
assert html.equals("""
<html>
<head>
<title>My Web Page</title>
</head>
<body>
<p>Hello, world</p>
</body>
</html>
""");
// 带格式化的字符串模板
record Rectangle(String name, double width, double height) {
double area() {
return width * height;
}
}
Rectangle[] zone = new Rectangle[] {
new Rectangle("Alfa", 17.8, 31.4),
new Rectangle("Bravo", 9.6, 12.4),
new Rectangle("Charlie", 7.1, 11.23),
};
String table = FMT. """
Description Width Height Area
%-12s\{ zone[0].name } %7.2f\{ zone[0].width } %7.2f\{ zone[0].height } %7.2f\{ zone[0].area() }
%-12s\{ zone[1].name } %7.2f\{ zone[1].width } %7.2f\{ zone[1].height } %7.2f\{ zone[1].area() }
%-12s\{ zone[2].name } %7.2f\{ zone[2].width } %7.2f\{ zone[2].height } %7.2f\{ zone[2].area() }
\{ " ".repeat(28) } Total %7.2f\{ zone[0].area() + zone[1].area() + zone[2].area() }
""";
assert table.equals("""
Description Width Height Area
Alfa 17.80 31.40 558.92
Bravo 9.60 12.40 119.04
Charlie 7.10 11.23 79.73
Total 757.69
""");
}
public static String getOfferType() {
return "gift";
}
record Request(String date, String time, String address) {
}这个功能当前是第一次预览,在Java22第二次预览,Java23的8.12版本中还没有展示字符串模板的第三次预览(JEP 465: String Templates),还不能确定什么时候可以正式用上。
JEP 442: 外部函数和内存API(Foreign Function & Memory API,FFM API,第三次预览)
FFM API经历过多次的预览及改进,从JEP 412(第一轮孵化)开始,逐步发展到JEP 442(第三次预览)。相较于前两次的改进主要体现在以下几个方面:
- 管理本地内存段的生命周期:在JEP 442中,通过新的Arena API集中管理本地内存段的生命周期,这使得内存管理更加高效和安全。
- 增强布局路径:引入了一个新的元素来解引用地址布局,这使得内存布局更加灵活和强大。
- 优化短暂使用期函数调用:提供了一个链接器选项,优化了对短暂使用期函数(例如clock_gettime)的调用,这些函数不会调用到Java代码。
- 本地链接器实现:引入了一个基于libffi的本地链接器实现,以便于移植。
- 移除VaList:在JEP 442中移除了VaList,这是对API的一次简化。
我们看下官方示例:
// 1. 在C库路径上查找名为radixsort的外部函数
Linker linker = Linker.nativeLinker();
SymbolLookup stdlib = linker.defaultLookup();
final MemorySegment memorySegment = stdlib.find("radixsort").orElseThrow();
FunctionDescriptor descriptor = FunctionDescriptor.ofVoid(
ValueLayout.ADDRESS,
ValueLayout.JAVA_INT,
ValueLayout.ADDRESS
);
MethodHandle radixsort = linker.downcallHandle(memorySegment, descriptor);
// 下面的代码将使用这个外部函数对字符串进行排序
// 2. 分配栈上内存来存储四个字符串
String[] javaStrings = {"mouse", "cat", "dog", "car"};
// 3. 使用try-with-resources来管理离堆内存的生命周期
try (Arena offHeap = Arena.ofConfined()) {
// 4. 分配一段离堆内存来存储四个指针
MemorySegment pointers = offHeap.allocateArray(ValueLayout.ADDRESS, javaStrings.length);
// 5. 将字符串从栈上内存复制到离堆内存
for (int i = 0; i < javaStrings.length; i++) {
MemorySegment cString = offHeap.allocateUtf8String(javaStrings[i]);
pointers.setAtIndex(ValueLayout.ADDRESS, i, cString);
}
// 6. 通过调用外部函数对离堆数据进行排序
radixsort.invoke(pointers, javaStrings.length, MemorySegment.NULL, '\0');
// 7. 将排序后的字符串从离堆内存复制回栈上内存
for (int i = 0; i < javaStrings.length; i++) {
MemorySegment cString = pointers.getAtIndex(ValueLayout.ADDRESS, i);
javaStrings[i] = cString.getUtf8String(0);
}
} // 8. 所有离堆内存在此处被释放
// 验证排序结果
assert Arrays.equals(javaStrings, new String[] {"car", "cat", "dog", "mouse"}); // true我们都知道,JNI也是可以调用外部代码的,那FFM API相较于JNI的优势在于:
- 更安全的内存访问:FFM API 提供了一种更安全和受控的方式来与本地代码交互,避免了JNI中常见的内存泄漏和数据损坏问题。
- 直接访问本地内存:FFM API 允许Java程序直接访问本地内存(即Java堆外的内存),这使得数据处理更加高效和灵活。
- 跨语言函数调用:FFM API 支持调用Java程序的外部函数,以与外部代码和数据一起操作,而无需依赖JNI的复杂机制。
- 更高效的集成:FFM API 使得Java与C、C++等语言编写的库集成更加方便和高效,特别是在数据处理和机器学习等领域。
- 减少代码复杂性:FFM API 提供了一种更简洁的API,减少了JNI中复杂的代码编写和维护工作。
- 更广泛的适用性:FFM API 不仅适用于简单的函数调用,还可以处理复杂的内存管理任务,如堆外内存的管理。
- 提高性能:FFM API 通过高效地调用外部函数和安全地访问外部内存,提高了程序的运行效率。
这个功能将在下一个版本 Java22 正式发布。
JEP 443: 未命名模式和变量(Unnamed Patterns and Variables,预览)
该特性使用下划线字符 _ 来表示未命名的模式和变量,从而简化代码并提高代码可读性和可维护性。
比如:
public static void main(String[] args) {
var _ = new Point(1, 2);
}
record Point(int x, int y) {
}这个可以用在任何定义变量的地方,比如:
... instanceof Point(_, int y)r instanceof Point _switch …… case Box(_)for (Order _ : orders)for (int i = 0, _ = sideEffect(); i < 10; i++)try { ... } catch (Exception _) { ... } catch (Throwable _) { ... }
只要是这个不准备用,可以一律使用_代替。
JEP 445: 未命名类和示例main方法(Unnamed Classes and Instance Main Methods,预览)
无论学习哪门语言,第一课一定是打印Hello, World!,Java中的写法是:
public class HelloWorld {
public static void main(String[] args) {
System.out.println ("Hello, World!");
}
}如果是第一次接触,一定会有很多疑问,public干啥的,main方法的约定参数args是什么鬼?然后老师就说,这就是模板,照着抄就行,不这样写不运行。
JEP 445特性后,可以简化为:
class HelloWorld {
void main() {
System.out.println ("Hello, World!");
}
}我们还可以这样写:
String greeting() { return "Hello, World!"; }
void main() {
System.out.println(greeting());
}虽然看起来没啥用,但是在JShell中使用,就比较友好了。
JEP 446: 作用域值(Scoped Values,预览)
作用域值(Scoped Values)在Java20孵化,在Java21预览,旨在提供一种安全且高效的方法来共享数据,无需使用方法参数。这一特性允许在不使用方法参数的情况下,将数据安全地共享给方法,优先于线程局部变量,特别是在使用大量虚拟线程时。
在多线程环境中,作用域值可以在线程内和线程间共享不可变数据,例如从父线程向子线程传递数据,从而解决了在多线程应用中传递数据的问题。此外,作用域值提高了数据的安全性、不变性和封装性,并且在多线程环境中使用事务、安全主体和其他形式的共享上下文的应用程序中表现尤为突出。
作用域值的主要特点:
- 不可变性:作用域值是不可变的,这意味着一旦设置,其值就不能更改。这种不可变性减少了并发编程中意外副作用的风险。
- 作用域生命周期:作用域值的生命周期仅限于 run 方法定义的作用域。一旦执行离开该作用域,作用域值将不再可访问。
- 继承性:子线程会自动继承父线程的作用域值,从而允许在线程边界间无缝共享数据。
在这个功能之前,在多线程间传递数据,我们有两种选择:
- 方法参数:显示参数传递;缺点是新增参数时修改联动修改一系列方法,如果是框架或SDK层面的,无法做到向下兼容。
ThreadLocal:在ThreadLocal保存当前线程变量。
使用过ThreadLocal的都清楚,ThreadLocal会有三大问题。
- 无约束的可变性:每个线程局部变量都是可变的。任何可以调用线程局部变量的
get方法的代码都可以随时调用该变量的set方法。即使线程局部变量中的对象是不可变的,每个字段都被声明为final,情况仍然如此。ThreadLocalAPI允许这样做,以便支持一个完全通用的通信模型,在该模型中,数据可以在方法之间以任何方向流动。这可能会导致数据流混乱,导致程序难以分辨哪个方法更新共享状态以及以何种顺序进行。 - 无界生存期:一旦通过
set方法设置了一个线程局部变量的副本,该值就会在该线程的生存期内保留,或者直到该线程中的代码调用remove方法。我们有时候会忘记调用remove,如果使用线程池,在一个任务中设置的线程局部变量的值如果不清除,可能会意外泄漏到无关的任务中,导致危险的安全漏洞(比如人员SSO)。对于依赖于线程局部变量的无约束可变性的程序来说,可能没有明确的点可以保证线程调用remove是安全的,可能会导致内存泄漏,因为每个线程的数据在退出之前都不会被垃圾回收。 - 昂贵的继承:当使用大量线程时,线程局部变量的开销可能会更糟糕,因为父线程的线程局部变量可以被子线程继承。(事实上,线程局部变量并不是某个特定线程的本地变量。)当开发人员选择创建一个继承了线程局部变量的子线程时,该子线程必须为之前在父线程中写入的每个线程局部变量分配存储空间。这可能会显著增加内存占用。子线程不能共享父线程使用的存储,因为ThreadLocal API要求更改线程的线程局部变量副本在其他线程中不可见。这也会有另一个隐藏的问题,子线程没有办法向父线程
set数据。
作用域值可以有效解决上面提到的问题,而且写起来更加优雅。
我们一起看下作用域值的使用:
// 声明一个作用域值用于存储用户名
public final static ScopedValue<String> USERNAME = ScopedValue.newInstance();
private static final Runnable printUsername = () ->
System.out.println(Thread.currentThread().threadId() + " 用户名是 " + USERNAME.get());
public static void main(String[] args) throws Exception {
// 将用户名 "Bob" 绑定到作用域并执行 Runnable
ScopedValue.where(USERNAME, "Bob").run(() -> {
printUsername.run();
new Thread(printUsername).start();
});
// 将用户名 "Chris" 绑定到另一个作用域并执行 Runnable
ScopedValue.where(USERNAME, "Chris").run(() -> {
printUsername.run();
new Thread(() -> {
new Thread(printUsername).start();
printUsername.run();
}).start();
});
// 检查在任何作用域外 USERNAME 是否被绑定
System.out.println("用户名是否被绑定: " + USERNAME.isBound());
}写起来干净利索,而且功能更强。
JEP 453: 结构化并发API(Structured Concurrency,预览)
JEP 453: 结构化并发API(Structured Concurrency API)旨在简化多线程编程,通过引入一个API来处理在不同线程中运行的多个任务作为一个单一工作单元,从而简化错误处理和取消操作,提高可靠性,并增强可观测性。本次发布是第一次预览。
结构化并发API提供了明确的语法结构来定义子任务的生命周期,并启用一个运行时表示线程间的层次结构。这有助于实现错误传播和取消以及并发程序的有意义观察。
Java使用异常处理机制来管理运行时错误和其他异常。当异常在代码中产生时,如何被传递和处理的过程称为异常传播。
在结构化并发环境中,异常可以通过显式地从当前环境中抛出并传播到更大的环境中去处理。
在Java并发编程中,非受检异常的处理是程序健壮性的重要组成部分。特别是对于非受检异常的处理,这关系到程序在遇到错误时是否能够优雅地继续运行或者至少提供有意义的反馈。
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
var task1 = scope.fork(() -> {
Thread.sleep(1000);
return "Result from task 1";
});
var task2 = scope.fork(() -> {
Thread.sleep(2000);
return "Result from task 2";
});
scope.join();
scope.throwIfFailed(RuntimeException::new);
System.out.println(task1.get());
System.out.println(task2.get());
} catch (Exception e) {
e.printStackTrace();
}在这个例子中,handle()方法使用StructuredTaskScope来并行执行两个子任务:task1和task2。通过使用try-with-resources语句自动管理资源,并确保所有子任务都在try块结束时正确完成或被取消。这种方式使得线程的生命周期和任务的逻辑结构紧密相关,提高了代码的清晰度和错误处理的效率。使用 StructuredTaskScope 可以确保一些有价值的属性:
- 错误处理与短路:如果task1或task2子任务中的任何一个失败,另一个如果尚未完成则会被取消。(这由 ShutdownOnFailure 实现的关闭策略来管理;还有其他策略可能)。
- 取消传播:如果在运行上面方法的线程在调用 join() 之前或之中被中断,则线程在退出作用域时会自动取消两个子任务。
- 清晰性:设置子任务,等待它们完成或被取消,然后决定是成功(并处理已经完成的子任务的结果)还是失败(子任务已经完成,因此没有更多需要清理的)。
- 可观察性:线程转储清楚地显示了任务层次结构,其中运行task1或task2的线程被显示为作用域的子任务。
上面的示例能够很好的解决我们的一个痛点,有两个可并行的任务A和B,A+B才是完整结果,任何一个失败,另外一个也不需要成功,结构化并发API就可以很容易的实现这个逻辑。
孵化功能
JEP 448: 向量API(Vector API,第六次孵化)
向量API的功能是提供一个表达向量计算的API,旨在通过引入向量计算API来提高Java应用程序的性能。这一API允许开发者在支持的CPU架构上可靠地编译为最佳向量指令,从而实现比等效的标量计算更高的性能。这些计算在运行时可靠地编译成支持的CPU架构上的最优向量指令,从而实现比等效标量计算更优的性能。
下面这个是官方给的示例:
// 标量计算示例
void scalarComputation(float[] a, float[] b, float[] c) {
for (int i = 0; i < a.length ; i++) {
c[i] = (a[i] * a[i] + b[i] * b[i]) * -1.0f;
}
}
// 使用向量API的向量计算示例
static final VectorSpecies<Float> SPECIES = FloatVector.SPECIES_PREFERRED;
void vectorComputation(float[] a, float[] b, float[] c) {
int i = 0;
int upperBound = SPECIES.loopBound(a.length);
for (; i < upperBound; i += SPECIES.length()) {
// FloatVector va, vb, vc;
var va = FloatVector.fromArray(SPECIES, a, i);
var vb = FloatVector.fromArray(SPECIES, b, i);
var vc = va.mul(va).add(vb.mul(vb)).neg();
vc.intoArray(c, i);
}
for (; i < a.length; i++) {
c[i] = (a[i] * a[i] + b[i] * b[i]) * -1.0f;
}
}向量API在Java中的独特优势在于其高效的并行计算能力、丰富的向量化指令集、跨平台的数据并行算法支持以及对机器学习的特别优化。
弃用
JEP 449: 启用Windows32位 x86支持(Deprecate the Windows 32-bit x86 Port for Removal)
旨在弃用并最终移除Windows 32位x86平台上的Java支持,原因是该平台已经逐渐被淘汰、性能限制和安全问题等。主要影响对象是OpenJDK的开发者和Windows 32位x86平台上的Java用户。
JEP 451: 准备禁止动态加载代理(Prepare to Disallow the Dynamic Loading of Agents)
该特性主要目的是通过在运行中的JVM中动态加载代理时发出警告,来帮助用户为将来的版本做好准备。这些警告旨在提高JVM的默认完整性,因为未来的版本将默认禁止动态加载代理。
文末总结
本文介绍了 Java21 新增的特性,完整的特性清单可以从 https://openjdk.org/projects/jdk/21/ 查看。后续内容会发布在 从小工到专家的 Java 进阶之旅 系列专栏中。
青山不改,绿水长流,我们下次见。
推荐阅读
- 从小工到专家的 Java 进阶之旅
- 一文掌握 Java8 Stream 中 Collectors 的 24 个操作
- 一文掌握 Java8 的 Optional 的 6 种操作
- 使用 Lambda 表达式实现超强的排序功能
- Java8 的时间库(1):介绍 Java8 中的时间类及常用 API
- Java8 的时间库(2):Date 与 LocalDate 或 LocalDateTime 互相转换
- Java8 的时间库(3):开始使用 Java8 中的时间类
- Java8 的时间库(4):检查日期字符串是否合法
- Java8 的新特性
- Java9 的新特性
- Java10 的新特性
- Java11 中基于嵌套关系的访问控制优化
- Java11 的新特性
- Java12 的新特性
- Java13 的新特性
- Java14 的新特性
- Java15 的新特性
- Java16 的新特性
- Java17 的新特性
- Java18 的新特性
- Java19 的新特性
- Java20 的新特性
- Java21 的新特性
- Java22 的新特性
- Java23 的新特性
- Java24 的新特性
你好,我是看山。游于码界,戏享人生。如果文章对您有帮助,请点赞、收藏、关注。我还整理了一些精品学习资料,关注公众号「看山的小屋」,回复“资料”即可获得。
个人主页:https://www.howardliu.cn
个人博文:Java 每半年就会更新一次新特性,再不掌握就要落伍了:Java21 的新特性
CSDN 主页:https://kanshan.blog.csdn.net/
CSDN 博文:Java 每半年就会更新一次新特性,再不掌握就要落伍了:Java21 的新特性
