
你好,我是看山。
本文收录在 《从小工到专家的 Java 进阶之旅》 系列专栏中。
从 2017 年开始,Java 版本更新遵循每六个月发布一次的节奏,LTS版本则每两年发布一次,以快速验证新特性,推动 Java 的发展。
概述
Java23 在 2024 年 9 月 17 日发布GA版本,共十二大特性:
- JEP 455: 模式匹配中使用原始类型(Primitive Types in Patterns, instanceof, and switch,预览)
- JEP 466: 类文件API(Class-File API,第二次预览)
- JEP 467: Markdown格式文档注释(Markdown Documentation Comments)
- JEP 469: 向量API(Vector API,第八次孵化)
- JEP 473: 流收集器(Stream Gatherers,第二次预览)
- JEP 471: 标记sun.misc.Unsafe中的内存管理方法为过时(Deprecate the Memory-Access Methods in sun.misc.Unsafe for Removal)
- JEP 474: ZGC:默认分代收集模式(ZGC: Generational Mode by Default)
- JEP 476: 模块导入声明(Module Import Declarations,预览)
- JEP 477: 隐式声明的类和实例方法(Implicitly Declared Classes and Instance Main Methods,第三次预览)
- JEP 480: 结构化并发(Structured Concurrency,第三次预览)
- JEP 481: 作用域值(Scoped Values,第三次预览)
- JEP 482: 灵活的构造函数主体(Flexible Constructor Bodies,第二次预览)
接下来我们一起看看这些特性。
JEP 467: Markdown格式文档注释(Markdown Documentation Comments)
Markdown是一种轻量级的标记语言,可用于在纯文本文档中添加格式化元素,具体语法可以参考Markdown Guide。本文就是使用Markdown语法编写的。
在Java注释中引入Markdown,目标是使API文档注释以源代码形式更易于编写和阅读。主要收益包括:
- 提高文档编写的效率:Markdown语法相比HTML更为简洁,开发者可以更快地编写和修改文档注释。
- 增强文档的可读性:Markdown格式的文档在源代码中更易于阅读,有助于开发者快速理解API的用途和行为。
- 促进文档的一致性:通过支持Markdown,可以确保文档风格的一致性,减少因格式问题导致的文档混乱。
- 简化文档维护:Markdown格式的文档注释更易于维护和更新,特别是在多人协作的项目中,可以减少因文档格式问题导致的沟通成本。
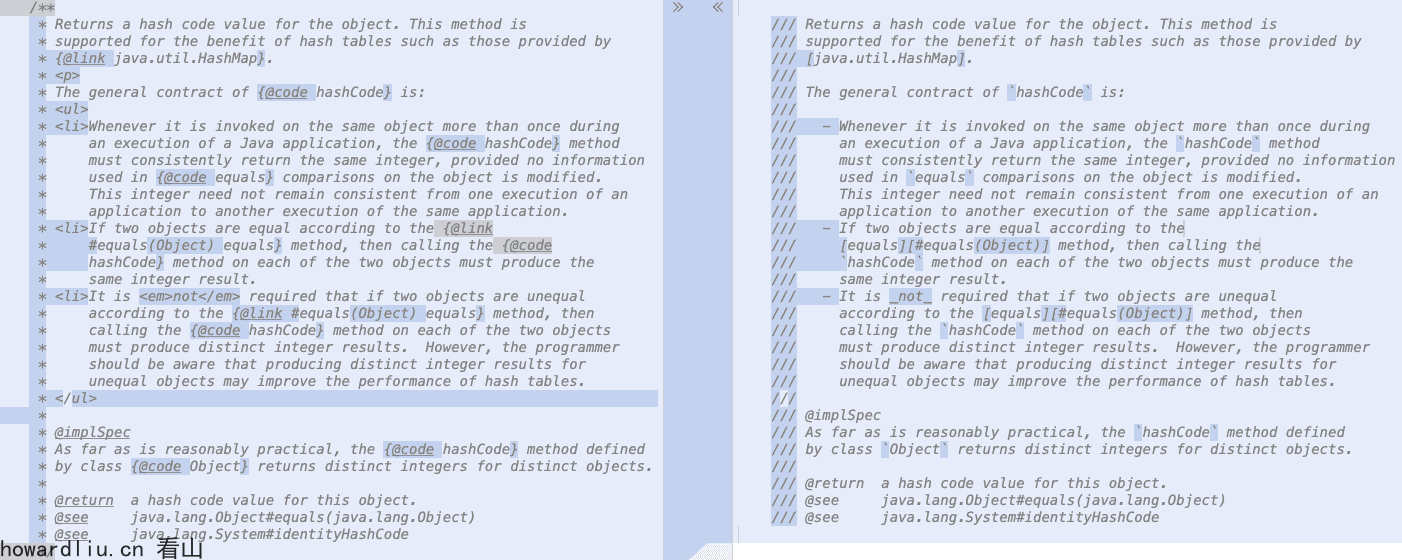
具体使用方式是在注释前面增加///,比如java.lang.Object.hashCode的注释:
/**
* Returns a hash code value for the object. This method is
* supported for the benefit of hash tables such as those provided by
* {@link java.util.HashMap}.
* <p>
* The general contract of {@code hashCode} is:
* <ul>
* <li>Whenever it is invoked on the same object more than once during
* an execution of a Java application, the {@code hashCode} method
* must consistently return the same integer, provided no information
* used in {@code equals} comparisons on the object is modified.
* This integer need not remain consistent from one execution of an
* application to another execution of the same application.
* <li>If two objects are equal according to the {@link
* #equals(Object) equals} method, then calling the {@code
* hashCode} method on each of the two objects must produce the
* same integer result.
* <li>It is <em>not</em> required that if two objects are unequal
* according to the {@link #equals(Object) equals} method, then
* calling the {@code hashCode} method on each of the two objects
* must produce distinct integer results. However, the programmer
* should be aware that producing distinct integer results for
* unequal objects may improve the performance of hash tables.
* </ul>
*
* @implSpec
* As far as is reasonably practical, the {@code hashCode} method defined
* by class {@code Object} returns distinct integers for distinct objects.
*
* @return a hash code value for this object.
* @see java.lang.Object#equals(java.lang.Object)
* @see java.lang.System#identityHashCode
*/如果使用JEP 467的Markdown方式:
/// Returns a hash code value for the object. This method is
/// supported for the benefit of hash tables such as those provided by
/// [java.util.HashMap].
///
/// The general contract of `hashCode` is:
///
/// - Whenever it is invoked on the same object more than once during
/// an execution of a Java application, the `hashCode` method
/// must consistently return the same integer, provided no information
/// used in `equals` comparisons on the object is modified.
/// This integer need not remain consistent from one execution of an
/// application to another execution of the same application.
/// - If two objects are equal according to the
/// [equals][#equals(Object)] method, then calling the
/// `hashCode` method on each of the two objects must produce the
/// same integer result.
/// - It is _not_ required that if two objects are unequal
/// according to the [equals][#equals(Object)] method, then
/// calling the `hashCode` method on each of the two objects
/// must produce distinct integer results. However, the programmer
/// should be aware that producing distinct integer results for
/// unequal objects may improve the performance of hash tables.
///
/// @implSpec
/// As far as is reasonably practical, the `hashCode` method defined
/// by class `Object` returns distinct integers for distinct objects.
///
/// @return a hash code value for this object.
/// @see java.lang.Object#equals(java.lang.Object)
/// @see java.lang.System#identityHashCode简单两种写法的差异,相同注释,Markdown的写法更加简洁:
JEP 474: ZGC:默认分代收集模式(ZGC: Generational Mode by Default)
分代ZGC从Java21正式发布,需要通过命令-XX:+UseZGC -XX:+ZGenerational显式使用分代ZGC。在Java23中,分代ZGC已作为ZGC默认方式,不需要显式指定了。在后续版本中,非分代ZGC将被删除。ZGC发展历程可以查看https://wiki.openjdk.org/display/zgc/Main。
基于「大部分对象朝生夕死」的分代假说,ZGC提供了分代版本,将内存划分为年轻代和老年代,并为这两种代分别维护不同的垃圾收集策略。
我们看下Hazelcast Jet on Generational ZGC中给出的测评效果:
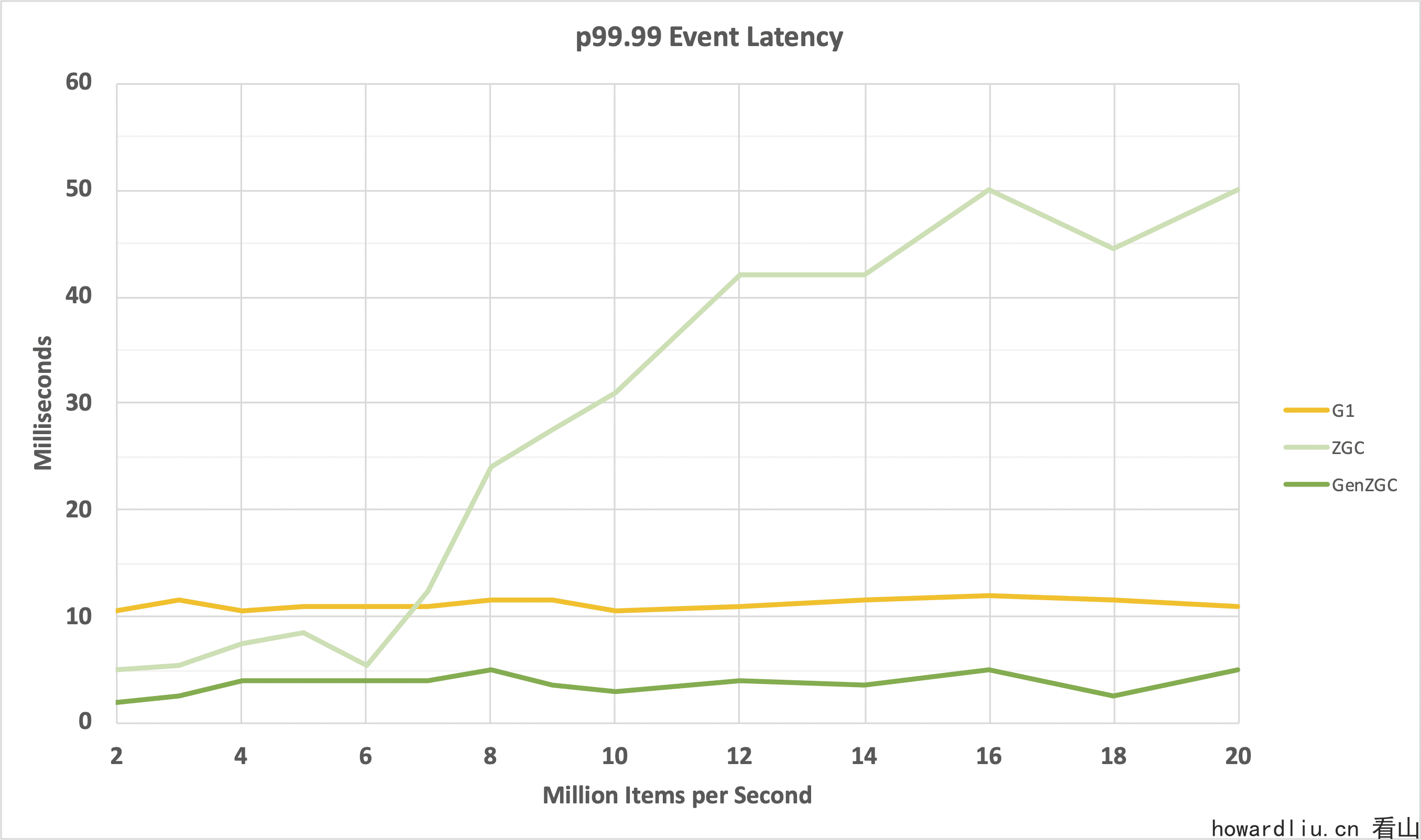
从上图可以看到,非分代 ZGC 在低负载下表现非常好,但随着分配压力的增加,延迟也会增加。使用分代 ZGC 后,即使在高负载下,延迟也非常低,而且延迟效果优于G1。
如果想用回非分代ZGC,需要通过命令-XX:+UseZGC -XX:-ZGenerational切换为非分代ZGC,启动过程会收到JVM的告警:“the ZGenerational option is deprecated is issued.”和“the non-generational mode is deprecated for removal is issued.”。
预览功能
JEP 455: 模式匹配中使用原始类型(Primitive Types in Patterns, instanceof, and switch,预览)
JEP 455 的目标是通过允许在所有模式上下文中使用原始类型来增强模式匹配,并扩展 instanceof 和 switch 以使其适用于所有原始类型。这旨在实现统一的数据探索,无论是原始类型还是引用类型。
在 Java 中,模式匹配主要针对引用类型,而原始类型在模式匹配中的使用受到限制。这导致了代码的冗余和不一致性。JEP 455 允许在 instanceof 和 switch 语句中直接使用原始类型,而无需进行额外的类型转换。这使得模式匹配更加灵活和强大,提高代码的可读性和一致性。
我们看下示例代码:
// 先看个例子
switch (x.getStatus()) {
case 0 -> "okay";
case 1 -> "warning";
case 2 -> "error";
default -> "unknown status: " + x.getStatus();
}
// default语句改造一下
switch (x.getStatus()) {
case 0 -> "okay";
case 1 -> "warning";
case 2 -> "error";
case int i -> "unknown status: " + i;
}
// 还可以增加检查值逻辑
switch (x.getYearlyFlights()) {
case 0 -> ...;
case 1 -> ...;
case 2 -> issueDiscount();
case int i when i >= 100 -> issueGoldCard();
case int i -> ... appropriate action when i > 2 && i < 100 ...
}
// 在数值精度问题场景中
if (i >= -128 && i <= 127) {
byte b = (byte)i;
... b ...
}
// 可以通过instanceof增强直接判断类型
if (i instanceof byte b) {
... b ...
}JEP 466: 类文件API(Class-File API,第二次预览)
Java中一直缺少官方的类文件操作API,想要操作class,我们需要借助第三方库,比如javassist、ASM、ByteBuddy等。从2017年开始,Java每半年有一次升级,特性更新频率增加,需要第三方库同步更新,是比较困难的。
还有一个原因是Java中使用了ASM实现jar、jlink等工具,以及lambda表达式等。这就会出现一个问题,Java版本N依赖了ASM版本M,如果Java N中有类API,ASM M中是不会有的,只有Java N发布后,ASM升级到M+1才会有,Java想要使用ASM M+1,需要升级到Java N+1。是不是很颠,一个官方基础语言,居然要依赖一个依赖这个语言的第三方工具。是可忍孰不可忍。
于是有了类文件API,目标是提供一个准确、完整、高性能且遵循Java虚拟机规范定义的类文件格式的API,最终也会替换JDK内部的ASM副本。
因为当前还是预览版,我们先简单看下官方示例:
如果要实现下面这段:
void fooBar(boolean z, int x) {
if (z)
foo(x);
else
bar(x);
}我们在ASM的写法:
ClassWriter classWriter = ...;
MethodVisitor mv = classWriter.visitMethod(0, "fooBar", "(ZI)V", null, null);
mv.visitCode();
mv.visitVarInsn(ILOAD, 1);
Label label1 = new Label();
mv.visitJumpInsn(IFEQ, label1);
mv.visitVarInsn(ALOAD, 0);
mv.visitVarInsn(ILOAD, 2);
mv.visitMethodInsn(INVOKEVIRTUAL, "Foo", "foo", "(I)V", false);
Label label2 = new Label();
mv.visitJumpInsn(GOTO, label2);
mv.visitLabel(label1);
mv.visitVarInsn(ALOAD, 0);
mv.visitVarInsn(ILOAD, 2);
mv.visitMethodInsn(INVOKEVIRTUAL, "Foo", "bar", "(I)V", false);
mv.visitLabel(label2);
mv.visitInsn(RETURN);
mv.visitEnd();在JEP 457中的写法:
ClassBuilder classBuilder = ...;
classBuilder.withMethod("fooBar", MethodTypeDesc.of(CD_void, CD_boolean, CD_int), flags,
methodBuilder -> methodBuilder.withCode(codeBuilder -> {
Label label1 = codeBuilder.newLabel();
Label label2 = codeBuilder.newLabel();
codeBuilder.iload(1)
.ifeq(label1)
.aload(0)
.iload(2)
.invokevirtual(ClassDesc.of("Foo"), "foo", MethodTypeDesc.of(CD_void, CD_int))
.goto_(label2)
.labelBinding(label1)
.aload(0)
.iload(2)
.invokevirtual(ClassDesc.of("Foo"), "bar", MethodTypeDesc.of(CD_void, CD_int))
.labelBinding(label2);
.return_();
});还可以这样写:
CodeBuilder classBuilder = ...;
classBuilder.withMethod("fooBar", MethodTypeDesc.of(CD_void, CD_boolean, CD_int), flags,
methodBuilder -> methodBuilder.withCode(codeBuilder -> {
codeBuilder.iload(codeBuilder.parameterSlot(0))
.ifThenElse(
b1 -> b1.aload(codeBuilder.receiverSlot())
.iload(codeBuilder.parameterSlot(1))
.invokevirtual(ClassDesc.of("Foo"), "foo",
MethodTypeDesc.of(CD_void, CD_int)),
b2 -> b2.aload(codeBuilder.receiverSlot())
.iload(codeBuilder.parameterSlot(1))
.invokevirtual(ClassDesc.of("Foo"), "bar",
MethodTypeDesc.of(CD_void, CD_int))
.return_();
});写法上比ASM更加优雅。
JEP 473: 流收集器(Stream Gatherers,第二次预览)
流收集器旨在增强Java Stream API、以支持自定义中间操作。这一特性允许开发者以更灵活和高效的方式处理数据流,从而提高流管道的表达能力和转换数据的能力。
流收集器通过引入新的中间操作Stream::gather(Gatherer),允许开发者定义自定义的转换实体(称为Gatherer),从而对流中的元素进行转换。这些转换可以是一对一、一对多、多对一或多对多的转换方式。此外,流收集器还支持保存以前遇到的元素,以便进行进一步的处理。
我们通过实例感受下这一特性的魅力:
public record WindowFixed<TR>(int windowSize) implements Gatherer<TR, ArrayList<TR>, List<TR>> {
public static void main(String[] args) {
var list = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9)
.gather(new WindowFixed<>(3))
.toList();
// [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
System.out.println(list);
}
public WindowFixed {
// Validate input
if (windowSize < 1) {
throw new IllegalArgumentException("window size must be positive");
}
}
@Override
public Supplier<ArrayList<TR>> initializer() {
// 创建一个 ArrayList 来保存当前打开的窗口
return () -> new ArrayList<>(windowSize);
}
@Override
public Integrator<ArrayList<TR>, TR, List<TR>> integrator() {
// 集成器在每次消费元素时被调用
return Gatherer.Integrator.ofGreedy((window, element, downstream) -> {
// 将元素添加到当前打开的窗口
window.add(element);
// 直到达到所需的窗口大小,
// 返回 true 表示希望继续接收更多元素
if (window.size() < windowSize) {
return true;
}
// 当窗口已满时,通过创建副本关闭窗口
var result = new ArrayList<TR>(window);
// 清空窗口以便开始新的窗口
window.clear();
// 将关闭的窗口发送到下游
return downstream.push(result);
});
}
// 由于此操作本质上是顺序的,因此无法并行化,因此省略了合并器
@Override
public BiConsumer<ArrayList<TR>, Downstream<? super List<TR>>> finisher() {
// 终结器在没有更多元素传递时运行
return (window, downstream) -> {
// 如果下游仍然接受更多元素且当前打开的窗口非空,则将其副本发送到下游
if (!downstream.isRejecting() && !window.isEmpty()) {
downstream.push(new ArrayList<TR>(window));
window.clear();
}
};
}
}该特性还是预览版,等正式发布后再细说。
JEP 476: 模块导入声明(Module Import Declarations,预览)
模块导入声明目标是增强 Java 编程语言,使其能够简洁地导入一个模块导出的所有包。这简化了模块库的重用,但并不要求导入代码本身必须在模块中。
在 Java 中,开发者经常需要从模块中导入多个包,这会导致代码中出现大量的 import 语句,增加了代码的冗余和复杂性。JEP 476 引入了一种新的导入声明方式,使得开发者可以更简洁地导入一个模块的所有包,从而提高代码的可读性和开发效率。
比如下面这段代码:
import java.util.Map; // or import java.util.*;
import java.util.function.Function; // or import java.util.function.*;
import java.util.stream.Collectors; // or import java.util.stream.*;
import java.util.stream.Stream; // (can be removed)
String[] fruits = new String[] { "apple", "berry", "citrus" };
Map<String, String> m =
Stream.of(fruits)
.collect(Collectors.toMap(s -> s.toUpperCase().substring(0,1),
Function.identity()));使用import导入了依赖的类,在JEP 476后,我们可以通过import module java.base;一行代码解决。
这种方式虽然简洁,但是可能存在问题,比如Date类,在java.util和java.sql中都有Date类,如果有场景需要这两个模块,就需要显式指明Date类的来源:
import module java.base; // exports java.util, which has a public Date class
import module java.sql; // exports java.sql, which has a public Date class
import java.sql.Date; // resolve the ambiguity of the simple name Date!
...
Date d = ... // Ok! Date is resolved to java.sql.Date
...JEP 477: 隐式声明的类和实例方法(Implicitly Declared Classes and Instance Main Methods,第三次预览)
隐式声明的类和实例方法的目标是简化 Java 语言,使得学生和初学者可以更容易地编写他们的第一个程序,而无需理解为大型程序设计的复杂语言特性。
无论学习哪门语言,第一课一定是打印Hello, World!,Java中的写法是:
public class HelloWorld {
public static void main(String[] args) {
System.out.println ("Hello, World!");
}
}如果是第一次接触,一定会有很多疑问,public干啥的,main方法的约定参数args是什么鬼?然后老师就说,这就是模板,照着抄就行,不这样写不运行。
现在可以简化为:
class HelloWorld {
void main() {
System.out.println ("Hello, World!");
}
}我们还可以这样写:
String greeting() { return "Hello, World!"; }
void main() {
System.out.println(greeting());
}main方法直接简化为名字和括号,甚至连类也不需要显性定义了。虽然看起来没啥用,但是在JShell中使用,就比较友好了。
本次预览新增了三个IO操作方法:
public static void println(Object obj);
public static void print(Object obj);
public static String readln(String prompt);想要快速实现控制台操作,可以这样写了:
void main() {
String name = readln("请输入姓名: ");
print("很高兴见到你, ");
println(name);
}作为一个老程序猿,也不得不哇塞一下。
JEP 480: 结构化并发(Structured Concurrency,第三次预览)
结构化并发API(Structured Concurrency API)旨在简化多线程编程,通过引入一个API来处理在不同线程中运行的多个任务作为一个单一工作单元,从而简化错误处理和取消操作,提高可靠性,并增强可观测性。本次发布是第一次预览。
结构化并发API提供了明确的语法结构来定义子任务的生命周期,并启用一个运行时表示线程间的层次结构。这有助于实现错误传播和取消以及并发程序的有意义观察。
Java使用异常处理机制来管理运行时错误和其他异常。当异常在代码中产生时,如何被传递和处理的过程称为异常传播。
在结构化并发环境中,异常可以通过显式地从当前环境中抛出并传播到更大的环境中去处理。
在Java并发编程中,非受检异常的处理是程序健壮性的重要组成部分。特别是对于非受检异常的处理,这关系到程序在遇到错误时是否能够优雅地继续运行或者至少提供有意义的反馈。
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
var task1 = scope.fork(() -> {
Thread.sleep(1000);
return "Result from task 1";
});
var task2 = scope.fork(() -> {
Thread.sleep(2000);
return "Result from task 2";
});
scope.join();
scope.throwIfFailed(RuntimeException::new);
System.out.println(task1.get());
System.out.println(task2.get());
} catch (Exception e) {
e.printStackTrace();
}在这个例子中,handle()方法使用StructuredTaskScope来并行执行两个子任务:task1和task2。通过使用try-with-resources语句自动管理资源,并确保所有子任务都在try块结束时正确完成或被取消。这种方式使得线程的生命周期和任务的逻辑结构紧密相关,提高了代码的清晰度和错误处理的效率。使用 StructuredTaskScope 可以确保一些有价值的属性:
- 错误处理与短路:如果task1或task2子任务中的任何一个失败,另一个如果尚未完成则会被取消。(这由 ShutdownOnFailure 实现的关闭策略来管理;还有其他策略可能)。
- 取消传播:如果在运行上面方法的线程在调用 join() 之前或之中被中断,则线程在退出作用域时会自动取消两个子任务。
- 清晰性:设置子任务,等待它们完成或被取消,然后决定是成功(并处理已经完成的子任务的结果)还是失败(子任务已经完成,因此没有更多需要清理的)。
- 可观察性:线程转储清楚地显示了任务层次结构,其中运行task1或task2的线程被显示为作用域的子任务。
上面的示例能够很好的解决我们的一个痛点,有两个可并行的任务A和B,A+B才是完整结果,任何一个失败,另外一个也不需要成功,结构化并发API就可以很容易的实现这个逻辑。
JEP 481: 作用域值(Scoped Values,第三次预览)
作用域值(Scoped Values)在Java20孵化,在Java21第一次预览,在Java22第二次预览,旨在提供一种安全且高效的方法来共享数据,无需使用方法参数。这一特性允许在不使用方法参数的情况下,将数据安全地共享给方法,优先于线程局部变量,特别是在使用大量虚拟线程时。
在多线程环境中,作用域值可以在线程内和线程间共享不可变数据,例如从父线程向子线程传递数据,从而解决了在多线程应用中传递数据的问题。此外,作用域值提高了数据的安全性、不变性和封装性,并且在多线程环境中使用事务、安全主体和其他形式的共享上下文的应用程序中表现尤为突出。
作用域值的主要特点:
- 不可变性:作用域值是不可变的,这意味着一旦设置,其值就不能更改。这种不可变性减少了并发编程中意外副作用的风险。
- 作用域生命周期:作用域值的生命周期仅限于 run 方法定义的作用域。一旦执行离开该作用域,作用域值将不再可访问。
- 继承性:子线程会自动继承父线程的作用域值,从而允许在线程边界间无缝共享数据。
在这个功能之前,在多线程间传递数据,我们有两种选择:
- 方法参数:显示参数传递;缺点是新增参数时修改联动修改一系列方法,如果是框架或SDK层面的,无法做到向下兼容。
ThreadLocal:在ThreadLocal保存当前线程变量。
使用过ThreadLocal的都清楚,ThreadLocal会有三大问题。
- 无约束的可变性:每个线程局部变量都是可变的。任何可以调用线程局部变量的
get方法的代码都可以随时调用该变量的set方法。即使线程局部变量中的对象是不可变的,每个字段都被声明为final,情况仍然如此。ThreadLocalAPI允许这样做,以便支持一个完全通用的通信模型,在该模型中,数据可以在方法之间以任何方向流动。这可能会导致数据流混乱,导致程序难以分辨哪个方法更新共享状态以及以何种顺序进行。 - 无界生存期:一旦通过
set方法设置了一个线程局部变量的副本,该值就会在该线程的生存期内保留,或者直到该线程中的代码调用remove方法。我们有时候会忘记调用remove,如果使用线程池,在一个任务中设置的线程局部变量的值如果不清除,可能会意外泄漏到无关的任务中,导致危险的安全漏洞(比如人员SSO)。对于依赖于线程局部变量的无约束可变性的程序来说,可能没有明确的点可以保证线程调用remove是安全的,可能会导致内存泄漏,因为每个线程的数据在退出之前都不会被垃圾回收。 - 昂贵的继承:当使用大量线程时,线程局部变量的开销可能会更糟糕,因为父线程的线程局部变量可以被子线程继承。(事实上,线程局部变量并不是某个特定线程的本地变量。)当开发人员选择创建一个继承了线程局部变量的子线程时,该子线程必须为之前在父线程中写入的每个线程局部变量分配存储空间。这可能会显著增加内存占用。子线程不能共享父线程使用的存储,因为ThreadLocal API要求更改线程的线程局部变量副本在其他线程中不可见。这也会有另一个隐藏的问题,子线程没有办法向父线程
set数据。
作用域值可以有效解决上面提到的问题,而且写起来更加优雅。
我们一起看下作用域值的使用:
// 声明一个作用域值用于存储用户名
public final static ScopedValue<String> USERNAME = ScopedValue.newInstance();
private static final Runnable printUsername = () ->
System.out.println(Thread.currentThread().threadId() + " 用户名是 " + USERNAME.get());
public static void main(String[] args) throws Exception {
// 将用户名 "Bob" 绑定到作用域并执行 Runnable
ScopedValue.where(USERNAME, "Bob").run(() -> {
printUsername.run();
new Thread(printUsername).start();
});
// 将用户名 "Chris" 绑定到另一个作用域并执行 Runnable
ScopedValue.where(USERNAME, "Chris").run(() -> {
printUsername.run();
new Thread(() -> {
new Thread(printUsername).start();
printUsername.run();
}).start();
});
// 检查在任何作用域外 USERNAME 是否被绑定
System.out.println("用户名是否被绑定: " + USERNAME.isBound());
}写起来干净利索,而且功能更强。
JEP 482: 灵活的构造函数主体(Flexible Constructor Bodies,第二次预览)
我们都知道,在子类的构造函数中,比如通过super(……)调用父类,在super之前是不允许有其他语句的。
大部分的时候这种限制都没问题,但是有时候不太灵活。如果想在super之前加上一些子类特有逻辑,比如想统计下子类构造耗时,就得重写一遍父类的实现。
除了有损灵活性,这种重写的做法也会造成父子类之间的关系变得奇怪。假设父类是SDK中的一个类,SDK升级时在父类构造函数增加了一些逻辑,我们项目中是无法继承这些逻辑的,某次需要升级SDK(比如低版本有安全风险),验证不完整的情况下,就很容易出现bug。
JEP 482 的目标是提高构造函数的可读性和可预测性,同时保持构造函数调用的自上而下的规则。通过允许在显式调用 super() 或 this() 前初始化字段,从而实现更灵活的构造函数主体。这一变化使得代码更具表现力。
我们看下示例代码:
public class PositiveBigInteger extends BigInteger {
public PositiveBigInteger(long value) {
if (value <= 0) {
throw new IllegalArgumentException("non-positive value");
}
super(value);
}
}孵化功能
JEP 469: 向量API(Vector API,第八次孵化)
向量API的功能是提供一个表达向量计算的API,旨在通过引入向量计算API来提高Java应用程序的性能。这一API允许开发者在支持的CPU架构上可靠地编译为最佳向量指令,从而实现比等效的标量计算更高的性能。这些计算在运行时可靠地编译成支持的CPU架构上的最优向量指令,从而实现比等效标量计算更优的性能。
下面这个是官方给的示例:
// 标量计算示例
void scalarComputation(float[] a, float[] b, float[] c) {
for (int i = 0; i < a.length ; i++) {
c[i] = (a[i] * a[i] + b[i] * b[i]) * -1.0f;
}
}
// 使用向量API的向量计算示例
static final VectorSpecies<Float> SPECIES = FloatVector.SPECIES_PREFERRED;
void vectorComputation(float[] a, float[] b, float[] c) {
int i = 0;
int upperBound = SPECIES.loopBound(a.length);
for (; i < upperBound; i += SPECIES.length()) {
// FloatVector va, vb, vc;
var va = FloatVector.fromArray(SPECIES, a, i);
var vb = FloatVector.fromArray(SPECIES, b, i);
var vc = va.mul(va).add(vb.mul(vb)).neg();
vc.intoArray(c, i);
}
for (; i < a.length; i++) {
c[i] = (a[i] * a[i] + b[i] * b[i]) * -1.0f;
}
}向量API在Java中的独特优势在于其高效的并行计算能力、丰富的向量化指令集、跨平台的数据并行算法支持以及对机器学习的特别优化。
弃用或废弃
JEP 471: 标记sun.misc.Unsafe中的内存管理方法为过时(Deprecate the Memory-Access Methods in sun.misc.Unsafe for Removal)
JEP 471 的目标是将 sun.misc.Unsafe 类中的内存访问方法标记为过时,并计划在未来版本中移除这些方法。这些方法包括直接访问 JVM 垃圾回收堆或非堆内存的操作。
sun.misc.Unsafe类自 2002 年引入以来,被广泛用于执行低级操作,如直接内存访问和线程调度。然而,这些方法存在安全隐患,可能导致内存泄漏和数据竞争等问题。随着 Java 平台的发展,出现了更安全的替代 API,如 VarHandle API(JEP 193, JDK 9)和 Foreign Function & Memory API(JEP 454, JDK 22),这些 API 提供了更安全和标准化的内存访问方式。
这一特性主要收益是:
- 提高安全性:移除不安全的内存访问方法,减少潜在的安全风险。
- 标准化内存管理:鼓励开发者使用标准 API,提高代码的可维护性和可移植性。
- 促进平台发展:为 Java 平台的未来发展铺平道路,支持更多高级特性。
JEP 471 将 sun.misc.Unsafe 中的内存访问方法标记为过时,并计划在未来版本中移除这些方法。具体步骤包括:
- 在 Java23 中标记这些方法为过时。
- 在 Java25 或之前版本中发出运行时警告。
- 在 Java26 或之后版本中默认抛出异常。
- 在后续版本中移除这些方法。
文末总结
本文介绍了 Java23 新增的特性,完整的特性清单可以从 https://openjdk.org/projects/jdk/23/ 查看。后续内容会发布在 从小工到专家的 Java 进阶之旅 系列专栏中。
青山不改,绿水长流,我们下次见。
推荐阅读
- 从小工到专家的 Java 进阶之旅
- 一文掌握 Java8 Stream 中 Collectors 的 24 个操作
- 一文掌握 Java8 的 Optional 的 6 种操作
- 使用 Lambda 表达式实现超强的排序功能
- Java8 的时间库(1):介绍 Java8 中的时间类及常用 API
- Java8 的时间库(2):Date 与 LocalDate 或 LocalDateTime 互相转换
- Java8 的时间库(3):开始使用 Java8 中的时间类
- Java8 的时间库(4):检查日期字符串是否合法
- Java8 的新特性
- Java9 的新特性
- Java10 的新特性
- Java11 中基于嵌套关系的访问控制优化
- Java11 的新特性
- Java12 的新特性
- Java13 的新特性
- Java14 的新特性
- Java15 的新特性
- Java16 的新特性
- Java17 的新特性
- Java18 的新特性
- Java19 的新特性
- Java20 的新特性
- Java21 的新特性
- Java22 的新特性
- Java23 的新特性
- Java24 的新特性
你好,我是看山。游于码界,戏享人生。如果文章对您有帮助,请点赞、收藏、关注。我还整理了一些精品学习资料,关注公众号「看山的小屋」,回复“资料”即可获得。
个人主页:https://www.howardliu.cn
个人博文:Java 每半年就会更新一次新特性,再不掌握就要落伍了:Java23 的新特性
CSDN 主页:https://kanshan.blog.csdn.net/
CSDN 博文:Java 每半年就会更新一次新特性,再不掌握就要落伍了:Java23 的新特性
