
本文源自并发编程网的翻译邀请,翻译的是 Jakob Jenkov 的 《软件架构》 中关于缓存技术的内容,虽然是 2014 年的文章,但是从软件架构层面上,并不过时。
缓存
缓存是一种加速数据查找(数据读取)的技术,直接读取本地缓存的数据,而不是从数据源读取数据,数据源包括数据库、其他远程系统。
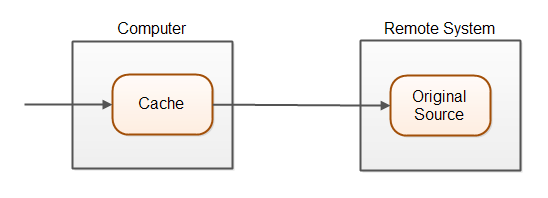
缓存是比源数据更靠近使用方的一块存储空间,可以更快的读取操作。缓存的存储介质一般是内存或磁盘,很多时候会选择内存作为缓存介质,但是内存缓存会在系统重启时丢失数据。
在软件系统中,数据缓存存在多层缓存级别或多层缓存系统。在 web 应用中,缓存至少有 3 种存储位置,如下图所示:
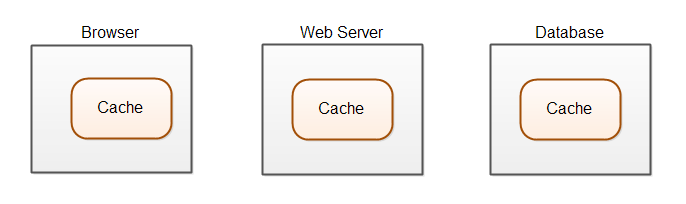
在 web 应用中,我们会使用各种各样的数据库存储数据,这些数据库可以将数据存放在内存中,以便我们直接读取,而不需要从磁盘中读取数据。web 服务器可以在内存中缓存图片、css 文件、js 文件等,不需要每次需要的时候从硬盘中访问文件。web 应用可以将从数据库读取的数据缓存起来,这样就不需要每次使用的时候都通过网络从数据库中读取数据了。最后,浏览器也可能存储静态文件和数据。在支持 HTML5 的浏览器中,有 localstorage 存储空间、应用数据缓存、本地 sql 存储等技术支持缓存。
当我们提到缓存的时候,有下面几项内容需要考虑:
- 写缓存
- 保持缓存和远程系统数据同步
- 管理缓存大小
我会在接下来的内容中讨论这几项内容。
写缓存
第一项挑战是从远程系统中读取数据写到缓存中,一般有两种方式:
- 提前写缓存
- 用时写缓存
提前写缓存是在系统启动的时候,就将需要的数据缓存起来。要做到这一点,需要提前知道哪些数据需要缓存。但是我们有时候并不知道哪些数据需要在系统启动时候就缓存起来。
用时写缓存是说,在第一次使用数据的时候,将数据缓存起来,之后就可以使用缓存中的数据了。这种操作的方式是,首先检查缓存中是否有数据,有就直接使用,如果没有,就从远程系统读取数据,然后写入缓存中。
下表中我列出了提前写入和用时写入的优缺点:
| 优点 | 缺点 | |
|---|---|---|
| 提前写缓存 | 比用时写入减少了第一次缓存数据的延迟 | 系统启动初始化缓存数据的时候,需要比较长的时间。而且,有可能缓存的数据永远不会被用到。 |
| 用时写缓存 | 缓存的数据都是需要被用到的数据,而且没有启动延迟 | 在第一次缓存数据的时候,用的时间比较长,可能导致用户体验不一致 |
当然,在真正实践过程中,我们可能两种方式并用:我们可以对热点数据使用提前缓存的方式,对其他数据使用用时缓存的方式。
保持缓存和远程系统数据同步
缓存数据的一个巨大挑战是保持缓存数据与远程系统数据保持同步,也就是数据一致。根据系统结构的不同,一般有不同的方式实现这个,我们来聊聊这几种方式。
直接式缓存
直写式缓存是允许读写缓存的一种方式,这种方式是,保存缓存数据的计算机,在将数据写入缓存的同时,将数据写到远程系统中。简单说就是,写入操作被写到远程系统中。
只有远程系统的数据只能被直写式缓存修改时,这种方式才起作用。如果所有的数据读写都要经过直写式缓存系统,那就很容易将写入的数据更新到远程系统中,保持缓存与远程系统数据的一致性。
基于过期时间
如果远程系统可以不依赖远程系统进行数据更新,那缓存和远程系统之间数据同步就很难通过直写式缓存方式保证了。
保持缓存数据同步的一种方法是,为数据设置一个缓存时间。当数据过期时,就把这些数据从缓存中清除。如果再次需要读取这些数据,可以从远程系统中读取最新的数据缓存起来。
数据过期时间取决于系统需要,有些类型的数据(比如文章),可能不需要随时的完全更新,可以设置 1 小时的过期时间。对于某些文章,你甚至可以忍受 24 小时的过期时间。
需要注意的是,如果过期时间比较短,可能会频繁读取远程系统,降低缓存的作用。
主动过期
还有一种方式是主动过期,是指主动更新缓存数据。比如,远程系统数据更新时,发送一条消息到缓存系统中,指示系统数据已被更新,可以将数据设置为过期。
主动过期的优点是,可能保证远程系统数据更新后,缓存数据被尽快的更新。还有一个附加好处是“基于过期时间”方式没有办法是实现的,就是不会频繁更新没有修改的数据。
主动过期的缺点是,需要能够检测远程系统数据的变化。如果远程系统是一个关系型数据库,可以被不同的机制更新数据,那每种更新机制都需要报告他们更新了哪些数据,否则,就没有办法向缓存数据的系统通知过期消息了。
管理缓存大小
管理缓存大小,是一个重要的方面。许多系统存储了大量数据,以至于不可能将所有数据都存储在缓存中。因此,需要一种机制来管理缓存的数据量。管理缓存大小通常是将不需要的缓存数据清除,来腾出足够的空间。一般有下面几种方式:
- 基于时间清理
- 先进先出(FIFO)
- 先进后出(FILO)
- 最少被使用
- 最小访问间隔
基于时间清理方式是类似于前面提到的基于时间过期。除了可以保持数据与远程系统同步,还能够减少缓存数据的大小。可以开启一个单独的监听线程,也可以在读写新值的时候清理数据。
先进先出清理方式意味着,当写入一个新的缓存的时候,就需要删除最早插入的缓存值。如果空间足够,也是可以不删除任何数据的。
先进后出的方式正好和先进先出相反,这种方式对于先存储的数据时热点数据的情况比较有用。
最少被使用清理方式是首先清理访问次数最少的缓存数据。这种方式的目的是避免清理热点数据,为了实现这种方式,需要记录缓存数据被访问的次数。需要注意一个问题,缓存中的旧值可能有较高的访问次数,这样就意味着这些旧值不会被清理。比如一篇旧文章的缓存,以前被访问过很多次,但是最近很少访问了,但是因为原来的访问量很高,尽管目前访问量较低,也不会被清理。为了避免这种情况,访问次数可以是针对 N 个小时统计。
最小访问间隔清理方式是将访问时间间隔考虑在内。访问某个缓存数据时,就需要标记访问该数据的时间并增加访问次数。第二次访问这个缓存数据时,就增加访问次数,并计算平均访问时间。那些曾经是热点数据,被频繁访问,但是最近访问时间间隔变长,访问频率下降的数据,其平均访问时间会降低,当降到足够低的时候,就会被清理。
有一种变化方式是,只计算最后 N 次访问的时间。N 可以是 100、1 或者其他任何有意义的数。每当访问计数到 N 时,访问计数被重置为 0,记录下来访问时间。这种方式可以更快的清理热度下降的数据。
还有一种变化方式是,定期重置访问计数,并且只使用最小访问的清理方式。比如,每缓存一个小时的数据,前一个小时的访问计数会存储在另一个变量中,以便决策清理时使用。下一个小时访问计数重置为 0。这种机制具有上次变化相同的效果。
最后两个变体之间的差异总结起来就是在每次缓存检查时,访问计数是否已达到 N,或者时间间隔是否已超过 Y。第一种方式是每隔 N 次访问一次系统时钟,而第二种方式在每次访问时都读取一次系统时钟(查看时间间隔是否已过期)。因为检查一个整数通常比读取系统时钟快,所以我会选择第一种方式。
请记住,即使使用缓存大小管理系统,也需要清理、读取和存储数据,以保证他们能够与远程系统保持一致。尽管缓存的数据被大量访问而驻留在系统中,有时候也需要与远程系统同步。
服务器集群中的缓存
单一服务中的缓存设计更加简单,因为你能够保证,所有写入操作都通过一个服务器,可以使用直写式缓存方式。但是在分布式集群中,情况会比较复杂,下图说明了这种情况:
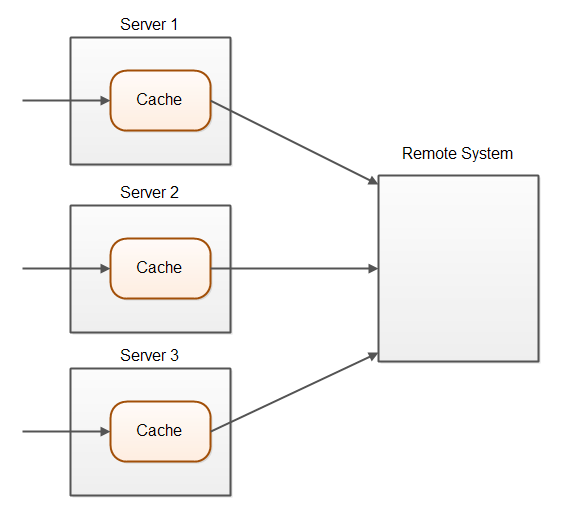
简单的使用直写式缓存只会更新写操作的服务器上的缓存,集群中其他服务器对此完全不知情,也就不会更新数据。
在服务器集群中,可以使用基于时间的过期策略或者主动过期策略,来保证缓存数据与远程系统的同步。
缓存产品
实现自己的缓存系统并不难弄,取决于是否需要深度定制。如果没有必要自己实现缓存系统,可以用已经现成的缓存产品。比如:
我不知道这些产品是否能够满足需要,但是我知道他们用的比较广泛。
你好,我是看山,公众号:看山的小屋,10 年老猿,开源贡献者。游于码界,戏享人生。
原文链接:Caching Techniques
翻译: https://www.howardliu.cn
译文链接: 软件架构-缓存技术
CSDN 主页:http://blog.csdn.net/liuxinghao
CSDN 博文:软件架构-缓存技术
