陆续的把Hadoop集群部署、HDFS的HA配置完成,把ResourceManager的HA配置好之后,Hadoop集群配置也算是完整了,可以满足小型中型生产环境Hadoop集群搭建的需要。如果真要搭建超大型的Hadoop集群,这些只能算是参考,还需要修改很多其他参数,使性能更好一些。
ResourceManager(RM)负责跟踪集群中资源使用情况,调度应用程序(比如MapReduce作业)。在Hadoop 2.4之前,ResourceManager存在单点故障,需要通过其他方式实现HA。官方给出的HA方案是Active/Standby两种状态ResourceManager的冗余方式,类似于HDFS的HA方案,也就是通过冗余消除单点故障。
HA架构
下图是ResourceManager HA方案架构图:
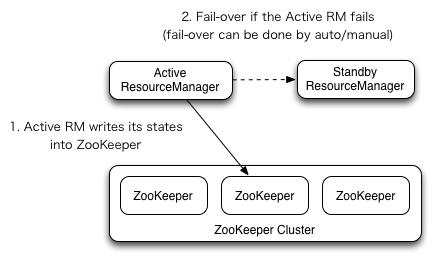
RM故障转移
ResourceManager HA是通过Active/Standby冗余架构实现的,在任何时间点,其中一个RM处于Active状态,其他RM处于Standby状态,Standby状态的RM就等着Active扑街或被撤。通过管理员命令或自动故障转移(需要开启自动故障转移配置),Standby就会转为Active状态,对外提供服务。
- 手动转换和故障转移:当未启用自动故障转移时,就需要管理员手动转换。首先将Active状态的RM转为Standby状态,然后将一个Standby状态的转为Active状态。这些操作都需要通过
yarn rmadmin命令来操作。 - 自动故障转移:RM可以通过内嵌的基于Zookeeper的Active/Standby选择器决定哪个RM应该是Active状态的。当Active性能下降或无响应时,一个Standby状态的RM就被推举出来,转为Active状态接管。这里不需要像HDFS的HA配置需要一个单独的ZKFS守护进程辅助完成切换,因为这个功能已经内嵌在RM中。
客户端、ApplicationMaster和NodeManager在故障转移时,会轮训这些RM节点,知道找到Active状态的RM。如果Active节点性能下降,他们会重新轮训查找新的Active状态的RM。默认的轮训扩展是org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider。可以通过实现org.apache.hadoop.yarn.client.RMFailoverProxyProvider,并配置yarn.client.failover-proxy-provider来实现自己的逻辑。
恢复RM状态
当启用ResourceManger重启状态恢复之后,新的Active状态的RM会加载上一个RM状态,并根据状态尽可能的恢复之前的操作。应用程序会定期检查,以避免丢失数据。状态存储需要对Active状态和Standby状态的RM都可见。目前,RMStateStore有两个持久化实现,FileSystemRMStateStore和ZKRMStateStore。ZKRMStateStore隐式的只允许一个RM写入操作,可以没有单独的防护机制就能够避免闹裂问题,所以是HA集群推荐的状态存储方式。使用ZKRMStateStore时,建议不要在zookeeper集群上设置zookeeper.DigestAuthenticationProvider.superDigest配置,以确保zk管理员无法访问YARN的信息。
部署
配置
大多数的故障转移功能可以使用各种配置进行调整,下表是必须的和重要的参数项。完整的配置和默认值参见yarn-default.xml。关于状态存储参见ResourceManger状态存储。
| 配置项 | 描述 |
|---|---|
| yarn.resourcemanager.zk-address | zookeeper集群地址,用于状态存储和内部的leader选举 |
| yarn.resourcemanager.ha.enabled | 开启RM的HA |
| yarn.resourcemanager.ha.rm-ids | RM逻辑id列表,以逗号分割,比如:rm1,rm2。 |
| yarn.resourcemanager.hostname.[rm-id] | 对于每个rm-id,需要给出hostname或ip地址。 |
| yarn.resourcemanager.address.[rm-id] | 对于每个rm-id,指定host:port地址,该配置会覆盖yarn.resourcemanager.hostname.rm-id。 |
| yarn.resourcemanager.scheduler.address.[rm-id] | 对于每个rm-id,指定ApplicationMasters申请资源的Scheduler的host:port地址,该配置会覆盖yarn.resourcemanager.hostname.rm-id。 |
| yarn.resourcemanager.resource-tracker.address.[rm-id] | 对于每个rm-id,指定NodeManager连接的host:port地址,该配置会覆盖yarn.resourcemanager.hostname.rm-id。 |
| yarn.resourcemanager.admin.address.[rm-id] | 对于每个rm-id,指定管理命令操作的host:port地址,该配置会覆盖yarn.resourcemanager.hostname.rm-id。 |
| yarn.resourcemanager.webapp.address.[rm-id] | 对于每个rm-id,指定RM的web应用host:port地址,如果设置yarn.http.policy是HTTPS_ONLY,就没必要设置该参数。该参数会覆盖yarn.resourcemanager.hostname.rm-id。 |
| yarn.resourcemanager.webapp.https.address.[rm-id] | 对于每个rm-id,指定RM的web应用host:port地址,如果设置yarn.http.policy是HTTP_ONLY,就没必要设置该参数。该参数会覆盖yarn.resourcemanager.hostname.rm-id。 |
| yarn.resourcemanager.ha.id | 用于识别HA的RM,可选配置。如果设置,需要确定所有的RM都有自己的ID。 |
| yarn.resourcemanager.ha.automatic-failover.enabled | 启用自动故障转移; 默认情况下,仅当HA被启用时才启用。 |
| yarn.resourcemanager.ha.automatic-failover.embedded | 启用自动故障转移时,使用嵌入式leader选举选择Active RM。 默认情况下,仅当HA被启用时才启用。 |
| yarn.resourcemanager.cluster-id | 集群标志,用于保证RM不会成为另一个集群的Active节点。 |
| yarn.client.failover-proxy-provider | 客户端使用,用于客户端、ApplicationMaster、NodeManager连接到新的Active的RM。 |
| yarn.client.failover-max-attempts | FailoverProxyProvider应该尝试的最大次数。 |
| yarn.client.failover-sleep-base-ms | 用于计算故障转移的休眠基准(单位是毫秒)。 |
| yarn.client.failover-sleep-max-ms | 故障转移休眠最长时间(单位是毫秒)。 |
| yarn.client.failover-retries | 尝试连接到RM的重试次数。 |
| yarn.client.failover-retries-on-socket-timeouts | 尝试连接到RM中可允许超时连接的次数。 |
配置示例(配置承接hadoop集群部署(yarn)中的,使用s107和s108作为RM双节点):
<!--Configurations for the state-store of ResourceManager-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>10.6.3.109:2181,10.6.3.110:2181,10.6.3.111:2181</value>
<description>ZooKeeper服务的地址,多个地址使用逗号隔开</description>
</property>
<!--Configurations for HA of ResourceManager-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
<description>是否启用HA,默认false</description>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
<description>最少2个</description>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>s107</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>s108</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-ha</value>
<description>集群HA的id,用于在ZooKeeper上创建节点,区分使用同一个ZooKeeper集群的不同Hadoop集群</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>s107:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>s108:8088</value>
</property>启动
可以在s107上直接通过start-yarn.sh启动YARN,这样在s107上会启动ResourceManager,在其他节点上会启动NodeManager。
需要注意的是s108上不会自己启动ResourceManager,需要手动启动。通过命令yarn-daemon.sh start resourcemanager手动启动。
管理命令
对于YARN的管理前面又说到,用的命令是yarn rmadmin,可以检查RM的健康状态、转换Active/Standby状态等,需要使用yarn.resourcemanager.ha.rm-ids参数配置的RM的id作为参数。比如,查看RM状态:
$ yarn rmadmin -getServiceState rm1
active
$ yarn rmadmin -getServiceState rm2
standby其他的命令可以通过yarn rmadmin -help获取。
Web管理页面
管理界面就是yarn.resourcemanager.webapp.address.[rm-id]配置的地址,如果访问的是Standby的RM地址,会自动重定向到Active状态的RM地址。About页面除外,可以访问About页面查看当前哪个节点是Active状态,哪个是Standby状态的。
参考文章
个人主页: https://www.howardliu.cn
个人博文: ResourceManager HA 配置
CSDN主页: http://blog.csdn.net/liuxinghao
CSDN博文: ResourceManager HA 配置