本文主要介绍storm中的基本概念,从基础上了解strom的体系结构,便于后续编程过程中作为基础指导。主要的概念包括:
- topology(拓扑)
- stream(数据流)
- spout(水龙头、数据源)
- bolt(螺栓,数据筛选处理)
- stream group(数据流分组)
- reliability(可靠性)
- task(任务)
- worker(执行者)
因为上述概念中除了可靠性reliability翻译起来比较合适,其他几个词实在找不到合适的对应词语,就直接使用原词。
另外一点需要注意的是,本文使用的storm-core版本是0.10.0,包路径为backtype.storm。因为阿里巴巴开源了jstorm,据说strom2.0之后使用jstorm作为master主干,从github上可以看到包路径修改为了org.apache.storm,如果发现有包路径错误的地方,请对应修改。
topology
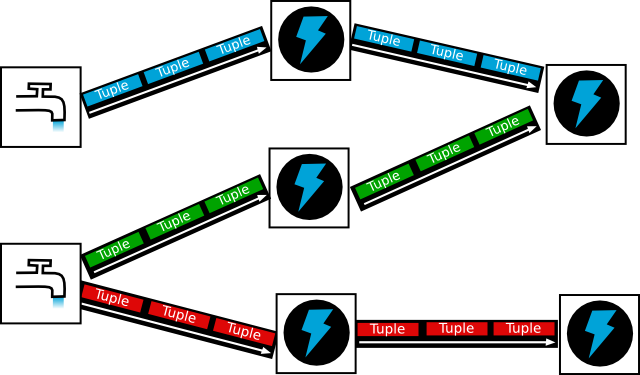
Storm实时运行应用包逻辑上成为一个topology,一个Storm的topology相当于MapReduce的job。关键的不同是MapReduce的job有明确的起始和结束,而Storm的topology会一直运行下去(除非进程被杀死或取消部署)。一个topology是有多个spout、bolt通过数据流分组连接起来的图结构。
本地调试
本地调试模拟了集群模式运行方式,对于开发和调试topology很有用。而且本地模式下运行topology与集群模式下类似,只是使用backtype.storm.LocalCluster来模拟集群状态。使用backtype.storm.LocalCluster#submitTopology方法提交topology,定义topology唯一名字、topology的配置(使用的是backtype.storm.Config对象)、以及topology对象(通过backtype.storm.topology.TopologyBuilder#createTopology方法创建)。通过backtype.storm.LocalCluster#killTopology杀掉指定topology,通过backtype.storm.LocalCluster#shutdown停止运行的本地集群模式。比如:
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(DEFAULT_TOPOLOGY_NAME, config, builder.createTopology());
Utils.sleep(100000);
cluster.killTopology(DEFAULT_TOPOLOGY_NAME);
cluster.shutdown();本地模式常用的配置如下:
- Config.TOPOLOGY_MAX_TASK_PARALLELISM:这个配置项主要用来设置每个组件线程数的上限。在生产环境中,每个topology中有很多并行线程,但是在本地调试过程中,没有必要存在这么多并行线程,可以通过这个配置来进行设置。
- Config.TOPOLOGY_DEBUG:设置为true,Storm将记录每个tuple提交后的日志信息,对于调试程序很有用。
集群模式运行
集群模式下运行topology与本地模式下类似,具体步骤如下:
定义topology(java下使用
backtype.storm.topology.TopologyBuilder#createTopology创建)通过
backtype.storm.StormSubmitter#submitTopology提交topology到集群。StormSubmitter需要的参数与LocalCluster`的参数一致:topology名、topology配置、topology对象。比如:Config conf = new Config(); conf.setNumWorkers(20); conf.setMaxSpoutPending(5000); StormSubmitter.submitTopology("mytopology", conf, topology);将自己的代码与依赖的代码打成jar包(除了storm自己的代码,storm自己的代码已经在classpath下了)。
如果使用的是Mava,可以使用Maven Assembly Plugin打包,在pom.xml中加入如下代码:<plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <archive> <manifest> <mainClass>com.path.to.main.Class</mainClass> </manifest> </archive> </configuration> </plugin>使用storm客户端将topology提交到集群,需要指定jar包路径、类名、以及提交到main方法的参数列表:
./bin/storm jar path/to/allmycode.jar org.me.MyTopology arg1 arg2 arg3可以使用
storm kill命令停止一个topology:./bin/storm kill topologyName
数据流
数据流是Storm核心定义的抽象概念,由无限制的tuple组成的序列,tuple包含一个或多个键值对列表,可以包含java自带的类型或者自定义的可序列化的类型。
每个数据流可以在定义时通过backtype.storm.topology.OutputFieldsDeclarer的declareStream方法指定id。默认的id是“default”(直接使用declare将使用默认id)。
在上面的topology图中,每个蓝色、绿色、红色的条带是一个数据流,每个数据流内部由tuple组成。
spout
spout是topology中数据流的数据入口,充当数据采集器功能,通常spout从外部数据源读取数据,将数据转化为tuple,然后将它们发送到topology中。spout可以是可靠的或不可靠的。可靠的spout能够保证在storm处理tuple出现异常情况下,能够重新发送该tuple,而不可靠的spout不再处理已发送的tuple。
spout通过backtype.storm.topology.OutputFieldsDeclarer的declareStream方法定义数据流,通过backtype.storm.spout.SpoutOutputCollector的emit方法发送tream。
backtype.storm.spout.ISpout#nextTuple方法是spout的主要方法,可以发送用于发送新的tuple,或直接return(不需要发送新的tuple时,可以直接return)。
当Storm检测到由某一spout发送的tuple成功处理后,将调用backtype.storm.spout.ISpout#ack方法;当调用失败,将调用backtype.storm.spout.ISpout#fail方法。具体可以查看后面的可靠性。
bolt
在topology中所有操作都是在bolt中执行的,它可以进行过滤、计算、连接、聚合、数据库读写,以及其他操作。可以将一个或多个spout作为输入,对数据进行运算后,选择性的输出一个或多个数据流。一个bolt可以做一些简单的数据变换,复杂的数据处理需要多个步骤或多个bolt。
bolt可以订阅一个或多个spout或bolt的数据,通过backtype.storm.topology.OutputFieldsDeclarer#declareStream方法定义输出的数据流,通过backtype.storm.topology.BasicOutputCollector#emit方法提交数据。
bolt通过backtype.storm.topology.InputDeclarer类的shuffleGrouping方法指定需要订阅的数据流,比如:declarer.shuffleGrouping("1", "stream_id"),同时InputDeclarer也提供了接收所有数据流的语法糖,比如:declarer.shuffleGrouping("1"),相当于declarer.shuffleGrouping("1", DEFAULT_STREAM_ID)。这个地方有点乱,简单的说,bolt B前面有一个spout A或bolt A,从A中发送一个id为a_id的数据流,如果B向只订阅id为a_id的数据流,就使用第一个方法,如果可以接收所有id类型的数据流,就用第二个方法。
该类型中主要执行的方法是cn.howardliu.demo.storm.kafka.wordCount.SentenceBolt#execute,用来获取新的tuple,并进行处理。同样使用backtype.storm.topology.BasicOutputCollector#emit方法发送新的tuple。bolt可以调用backtype.storm.task.OutputCollector#ack方法来通知Storm该tuple已经处理完成。
数据流分组
定义topology的很重要的一部分就是定义数据流数据流应该发送到那些bolt中。数据流分组就是将数据流进行分组,按需要进入不同的bolt中。可以使用Storm提供的分组规则,也可以实现backtype.storm.grouping.CustomStreamGrouping自定义分组规则。Storm定义了8种内置的数据流分组方法:
- Shuffle grouping(随机分组):随机分发tuple给bolt的各个task,每个bolt实例接收到相同数量的tuple;
- Fields grouping(按字段分组):根据指定字段的值进行分组。比如,一个数据流按照”user-id”分组,所有具有相同”user-id”的tuple将被路由到同一bolt的task中,不同”user-id”可能路由到不同bolt的task中;
- Partial Key grouping(部分key分组):数据流根据field进行分组,类似于按字段分组,但是将在两个下游bolt之间进行均衡负载,当资源发生倾斜的时候能够更有效率的使用资源。The Power of Both Choices: Practical Load
Balancing for Distributed Stream Processing Engines提供了更加详细的说明; - All grouping(全复制分组):将所有tuple复制后分发给所有bolt的task。小心使用。
- Global grouping(全局分组):将所有的tuple路由到唯一一个task上。Storm按照最小的task ID来选取接收数据的task;(注意,当时用全局分组是,设置bolt的task并发是没有意义的,因为所有tuple都转发到一个task上。同时需要注意的是,所有tuple转发到一个jvm实例上,可能会引起storm集群某个jvm或服务器出现性能瓶颈或崩溃)
- None grouping(不分组):这种分组方式指明不需要关心分组方式。实际上,不分组功能与随机分组相同。预留功能。
- Direct grouping(指向型分组):数据源会调用emitDirect来判断一个tuple应该由哪个storm组件接收,只能在声明了指向型的数据流上使用。
- Local or shuffle grouping(本地或随机分组):当同一个worker进程中有目标bolt,将把数据发送到这些bolt中。否则,功能将与随机分组相同。该方法取决与topology的并发度,本地或随机分组可以减少网络传输,降低IO,提高topology性能。
可靠行
storm可以保证每一个spout发出的tuple能够被完整处理,通过跟踪tuple树上的每个tuple,检查是否被成功处理。每个topology有一个超时时间,如果storm检查到某个tuple已经超时,将重新发送该tuple。为了使用这种特性,需要定义tuple的起点,以及tuple被成功处理。更多内容查看Guaranteeing message processing。
task
task是spout和bolt的实例,他们的nextTuple()和execute()方法会被executors线程调用执行。根据数据流分组来确定如何从某个task中的tuple发送到其他的task。
worker
topology运行在一个或多个worker进程上,worker是jvm虚拟机,运行topology所有task的一部分。比如,topology的并发是300,有50个worker,那每个worker就有6个task。Storm会平衡所有worker的task数量。通过Config.TOPOLOGY_WORKERS来设置topology的worker数量。
个人主页: https://www.howardliu.cn
个人博文: storm笔记:storm基本概念
CSDN主页: http://blog.csdn.net/liuxinghao
CSDN博文: storm笔记:storm基本概念